编译器设计 - 编译器的阶段
编译过程是一个由多个阶段组成的序列。每个阶段从前一阶段接收输入,具有源程序的自身表示形式,并将其输出传递给编译器的下一阶段。让我们来了解编译器的各个阶段。
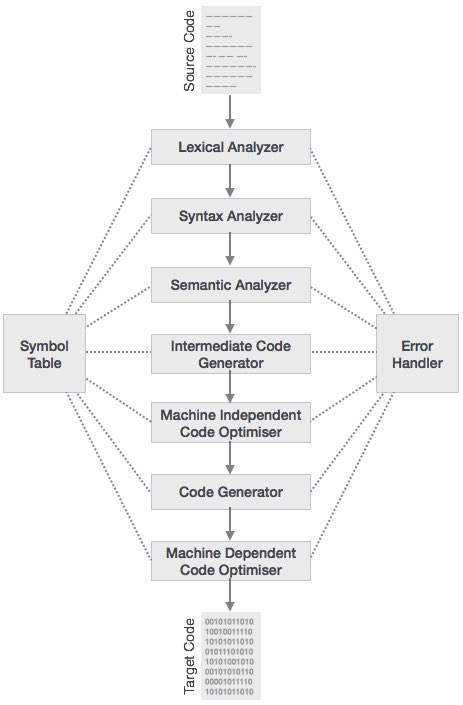
词法分析
扫描器的第一阶段充当文本扫描器。此阶段将源代码扫描为字符流,并将其转换为有意义的词法单元。词法分析器将这些词法单元表示为以下形式的 token:
<token-name, attribute-value>
语法分析
下一阶段称为语法分析或 parsing。它以词法分析产生的 token 作为输入,并生成解析树(或语法树)。在此阶段,会根据源代码的文法检查 token 的排列,即 parser 检查由 token 构成的表达式在语法上是否正确。
语义分析
语义分析检查构建的解析树是否遵循语言规则。例如,值赋值是否在兼容的数据类型之间,以及将字符串与整数相加等。此外,语义分析器会跟踪标识符、其类型和表达式;标识符在使用前是否已声明等。语义分析器会生成带注解的语法树作为输出。
中间代码生成
语义分析之后,编译器会为目标机器生成源代码的中间代码。它表示某个抽象机器的程序,介于高级语言和机器语言之间。此中间代码的生成方式应使其更容易翻译为目标机器代码。
代码优化
下一阶段对中间代码进行代码优化。优化可以视为删除不必要的代码行,并重新排列语句序列,以加速程序执行,同时不浪费资源(CPU、内存)。
代码生成
在此阶段,代码生成器接收优化的中间代码表示,并将其映射到目标机器语言。代码生成器将中间代码翻译为(通常)可重定位的机器代码指令序列。此机器代码指令序列执行与中间代码相同的任务。
符号表
符号表是贯穿编译器所有阶段维护的数据结构。在此存储所有标识符的名称及其类型。符号表使编译器能够快速搜索标识符记录并检索它。符号表还用于作用域管理。