使用 Prometheus 和 Grafana 进行日志记录和监控
监控和日志记录对于在 Kubernetes 中管理应用程序至关重要。如果没有对集群健康状况和性能的适当可见性,排查问题将变得困难。这就是 Prometheus 和 Grafana 的用武之地。Prometheus 是一个专为 Kubernetes 设计的强大监控系统,而 Grafana 提供了丰富的可视化功能。
在本章中,我们将探讨如何在 Kubernetes 中设置 Prometheus 和 Grafana,收集 metrics,可视化数据,并配置警报以确保主动监控。到最后,我们将拥有一个完全集成的 Kubernetes 环境中的功能完整的监控系统。
为什么监控很重要
随着应用程序复杂性的增加,监控帮助我们 −
- 检测性能问题 − 在用户遇到问题之前发现响应缓慢、内存泄漏或高 CPU 使用率。
- 确保系统可靠性 − 通过及早检测故障来维持正常运行时间。
- 分析趋势 − 了解应用程序随时间的变化行为。
- 针对问题发出警报 − 当关键 metrics 超过阈值时接收通知。
了解 Prometheus
Prometheus 是一个开源监控系统,专为 Kubernetes 等动态云环境设计。它通过从已插桩的应用程序抓取 metrics 并将其存储在时间序列数据库中来工作。Prometheus 提供 −
- 带有键值标签的多维数据模型
- 用于数据分析的强大查询语言 (PromQL)
- 基于拉取的模型,Prometheus 从目标抓取 metrics
- 通过 Alertmanager 内置警报功能
- 与 Kubernetes Service Discovery 的集成
Prometheus 关键概念
- Targets:Prometheus 抓取 metrics 的服务(例如 Kubernetes nodes、pods、applications)。
- Jobs:配置中定义的目标组。
- Metrics:从目标收集的时间序列数据。
- PromQL (Prometheus Query Language):用于查询和分析存储的 metrics。
- Alerting rules:定义触发警报的条件。
了解 Grafana
Grafana 是一个可视化工具,它将原始 metrics 转换为丰富的仪表板。它连接到 Prometheus 并提供 −
- 交互式图表、图形和表格
- 用于实时监控的自定义仪表板
- 通过 email、Slack 或其他集成进行警报和通知
- 支持多种数据源 (Prometheus、Loki、Elasticsearch 等)
在 Kubernetes 中设置 Prometheus 和 Grafana
开始之前,我们将在 Kubernetes 集群中部署 Prometheus 和 Grafana。最简单的方法是使用 Helm,它是 Kubernetes 的包管理器。
前提条件
在开始之前,我们将确保:
- Kubernetes 集群已启动并运行。
- kubectl 已配置为与集群通信。
- Helm 已安装在我们的系统上。
安装 Prometheus 和 Grafana
我们首先添加 Prometheus Helm 仓库 −
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
输出
"prometheus-community" has been added to your repositories
更新 Helm 仓库 −
$ helm repo update
输出
Hang tight while we grab the latest from your chart repositories... ...Successfully got an update from the "prometheus-community" chart repository ...Successfully got an update from the "bitnami" chart repository Update Complete. Happy Helming!
使用 Helm 安装 Prometheus Stack −
$ helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
输出
NAME: prometheus
LAST DEPLOYED: Mon Mar 10 11:14:18 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace monitoring get pods -l "release=prometheus"
Get Grafana 'admin' user password by running:
kubectl --namespace monitoring get secrets prometheus-grafana
-o jsonpath="{.data.admin-password}" | base64 -d ; echo
Access Grafana local instance:
export POD_NAME=$(kubectl --namespace monitoring get pod -l
"app.kubernetes.io/name=grafana,app.kubernetes.io/instance=prometheus" -oname)
kubectl --namespace monitoring port-forward $POD_NAME 3000
这会在 monitoring namespace 下安装 Prometheus、Grafana 和 Alertmanager。
验证 Prometheus Pods 是否正在运行 −
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE alertmanager-prometheus-kube-prometheus-alertmanager-0 0/2 Init:0/1 0 76s prometheus-grafana-54d864bf96-t2qjr 0/3 ContainerCreating 0 3m30s prometheus-kube-prometheus-operator-dd4b85cc8-qjjmq 1/1 Running 0 3m30s prometheus-kube-state-metrics-888b7fd55-lv5mq 1/1 Running 0 3m30s prometheus-prometheus-kube-prometheus-prometheus-0 0/2 Init:0/1 0 76s prometheus-prometheus-node-exporter-wvgxw 1/1 Running 0 3m30s
这确认了一些必需的服务正在运行,而其他服务仍在初始化中。
访问 Prometheus UI
要访问此 UI,我们首先对 Prometheus pod 进行 port-forward −
$ kubectl port-forward prometheus-prometheus-kube-prometheus-prometheus-0 9090 -n monitoring
输出
Forwarding from 127.0.0.1:9090 -> 9090 Forwarding from [::1]:9090 -> 9090
现在,我们可以在浏览器中访问 http://localhost:9090 来访问 Prometheus UI。
访问 Grafana UI
我们首先使用以下命令对 Grafana pod 进行 port-forward −
$ kubectl port-forward prometheus-grafana-54d864bf96-t2qjr 3000 -n monitoring
输出
Forwarding from 127.0.0.1:3000 -> 3000 Forwarding from [::1]:3000 -> 3000
现在,我们可以在网页浏览器中打开 http://localhost:3000,并使用以下信息登录 −
- 用户名: admin
- 密码: prom-operator (kubectl --namespace monitoring get secrets prometheus-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echo)
Kubernetes 中的指标收集
Prometheus 会自动发现并抓取 Kubernetes 组件的指标,包括:
- Node metrics (CPU、内存、磁盘使用量)
- Pod 和 container metrics (资源消耗、重启、错误)
- Kubernetes API metrics (事件日志、调度器统计)
要手动暴露应用程序的指标,我们可以使用 Exporter。
示例:Node Exporter(收集系统指标)
$ helm install node-exporter prometheus-community/prometheus-node-exporter --namespace monitoring
输出
NAME: node-exporter
LAST DEPLOYED: Mon Mar 10 13:42:25 2025
NAMESPACE: monitoring
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
1. Get the application URL by running these commands:
export POD_NAME=$(kubectl get pods --namespace monitoring -l
"app.kubernetes.io/name=prometheus-node-exporter,app.kubernetes.io/instance=node-exporter" -o
jsonpath="{.items[0].metadata.name}")
echo "Visit http://127.0.0.1:9100 to use your application"
kubectl port-forward --namespace monitoring $POD_NAME 9100
在端口 9100 上暴露 Node Exporter:
$ export POD_NAME=$(kubectl get pods --namespace monitoring -l
"app.kubernetes.io/name=prometheus-node-exporter,app.kubernetes.io/instance=node-exporter" -o
jsonpath="{.items[0].metadata.name}")
$ kubectl port-forward --namespace monitoring $POD_NAME 9100
访问 http://127.0.0.1:9100 查看系统指标。
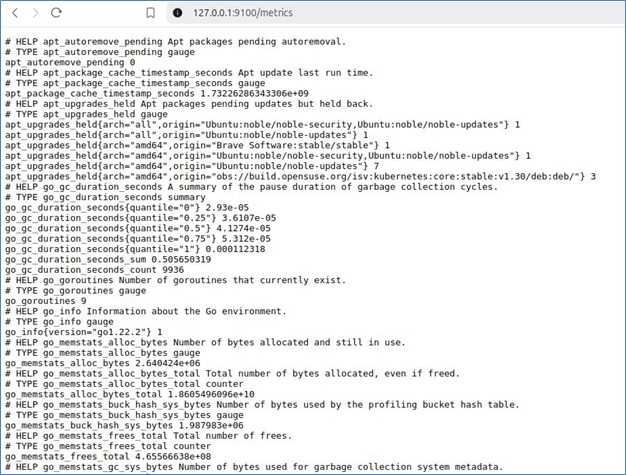
这会收集主机级别的系统指标,包括 CPU、内存、磁盘使用量、文件系统统计和网络活动。
Prometheus 中的监控目标
Prometheus 从各种来源收集指标,这些来源称为 targets。这些 targets 可以包括 Prometheus server 本身、Node Exporter、应用程序实例以及其他以 Prometheus 兼容格式暴露指标的服务。
当 Prometheus 抓取一个 target 时,它会为其分配以下状态之一:
- Up(Healthy): target 处于活动状态并响应 Prometheus 的抓取。
- Down (Unhealthy): target 不可达,或者 Prometheus 无法检索指标。
- Unknown:target 尚未被抓取或配置错误。
Targets 页面显示的关键细节
- Endpoint − Prometheus 抓取指标的 URL。
- State − target 是 up、down 还是 unknown。
- Labels − 用于在 Prometheus 中查询和分组的标识符。
- Last Scrape − Prometheus 上次成功抓取 target 的时间。
- Scrape Duration − 收集指标所花费的时间。
- Error − 如果 Prometheus 抓取 target 失败,会显示错误消息。
在 Prometheus 中配置 Targets
Targets 在 Prometheus 配置文件 (prometheus.yml) 的 scrape_configs 部分中定义。
以下是为监控 Prometheus 本身和 Node Exporter 的示例配置:
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100']
每个 job_name 代表一个被监控的服务,targets 指定 Prometheus 抓取的端点。
查看 Target 指标
配置完成后,访问 http://localhost:9090/targets 检查每个 target 的状态。点击端点将显示服务暴露的原始指标。这些指标随后可以在 Prometheus 中查询,并在 Grafana 等工具中可视化以获得更好的洞察。
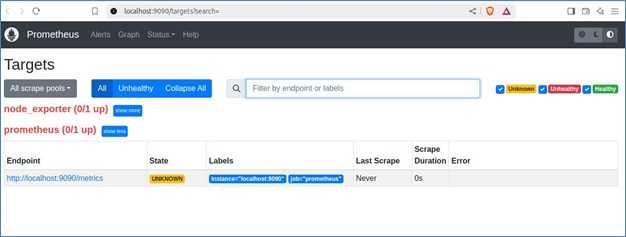
使用 Grafana 可视化指标
现在让我们了解如何使用 Grafana 可视化指标:
将 Prometheus 连接到 Grafana
首先,通过访问 http://localhost:3000 登录 Grafana,并使用 admin 凭据。
接下来,导航到欢迎页面并转到 Data Sources。
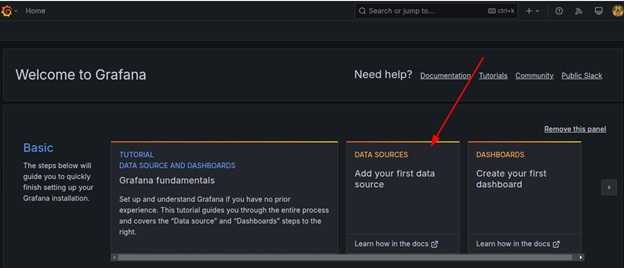
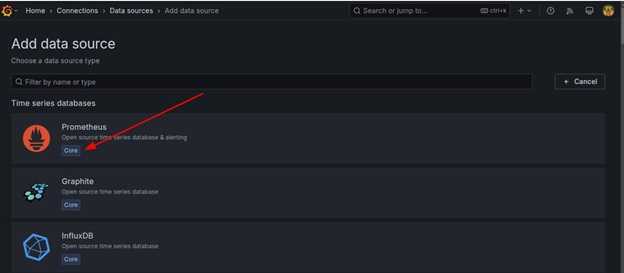
点击 Add Data Source 并选择 Prometheus 作为数据源类型。
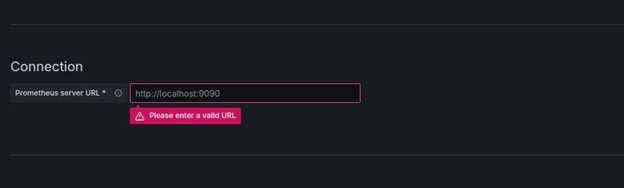
在 URL 字段中,输入 http://localhost:9090 作为 Prometheus server URL。
点击 Save & Test。
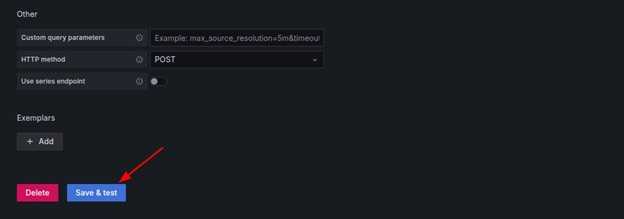
以下输出确认连接成功:

使用自定义可视化创建 Grafana 仪表板
要实现此功能,首先点击 Create → Dashboard。
接下来,点击添加可视化按钮。
选择 prometheus(默认)作为数据源。
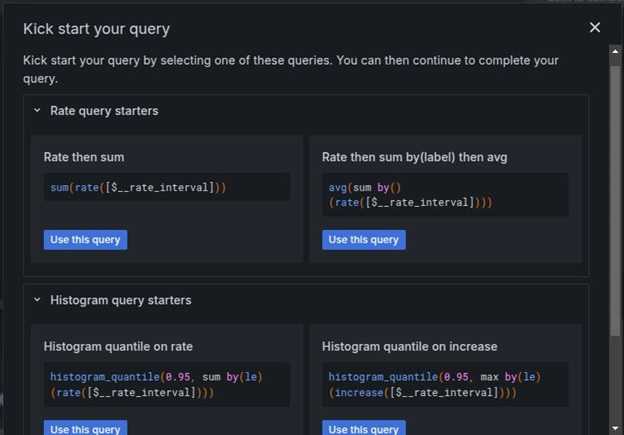
在 Query 部分,点击 kick start your query 按钮来选择查询类型。使用 Rate then sum 作为查询。
然后,输入查询,例如 node_cpu_seconds_total,并点击相关选项。
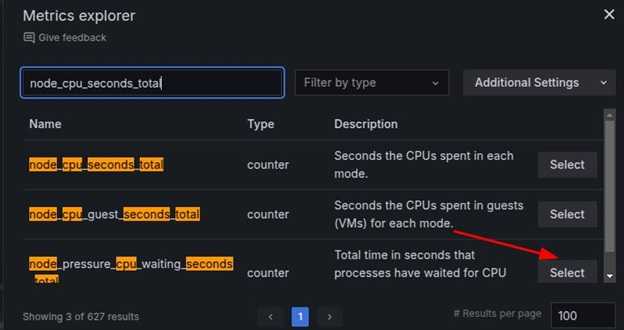
选择 time series 作为可视化类型(例如 Graph、Gauge、Table 或 Heatmap),并点击 run queries 完成查询。
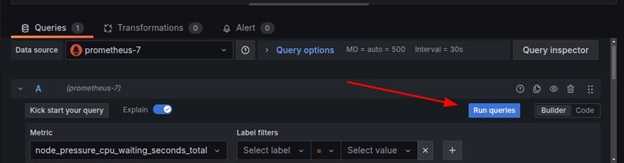
现在,原始数据可以被可视化。
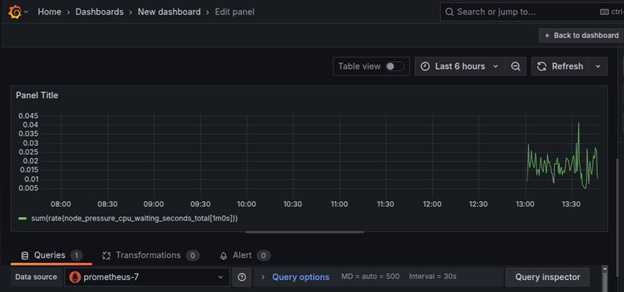
用于可视化的其他示例查询
- 每个 Pod 的 CPU 使用量:sum(rate(container_cpu_usage_seconds_total{namespace="monitoring"}[5m])) by (pod)
- 每个 Node 的内存使用量:sum(container_memory_usage_bytes) by (node)
- 每个 Container 的磁盘 I/O 读取:rate(container_fs_reads_bytes_total[5m])
- 每个 Pod 的网络流量:sum(rate(container_network_receive_bytes_total[5m])) by (pod)
在 Grafana 中导入预构建的 Kubernetes 仪表板
Grafana 支持使用 JSON 文件导入仪表板,这使得重用预配置的可视化变得非常容易。要导入仪表板,请按照以下步骤操作:
获取 JSON 仪表板文件
从 Grafana 官方网站下载预构建的 Kubernetes 监控仪表板,或将现有仪表板导出为 JSON 文件。
在 Grafana 中导入 JSON 文件
- 转到 Dashboards → Import。
- 点击 Upload JSON file 并选择您的预配置仪表板文件。
- 或者,将 JSON 内容粘贴到 Import via JSON 中。
选择数据源
选择正确的 Prometheus 数据源,以确保导入的仪表板检索到预期的 metrics。
导入仪表板
点击 Import 以加载详细的 Kubernetes 监控仪表板。
导入后,可以通过添加额外面板或调整警报阈值来自定义仪表板。
在 Prometheus 中配置警报
为了在问题发生时接收警报,我们可以配置 Alertmanager。
创建警报规则
将以下内容保存为 alerts.yaml。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: high-cpu-alert
namespace: monitoring
spec:
groups:
- name: example.rules
rules:
- alert: HighCPUUsage
expr: (100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)) > 80
for: 2m
labels:
severity: warning
annotations:
summary: "检测到高 CPU 使用率"
description: "CPU 使用率已超过 80% 超过 2 分钟"
应用该规则:
$ kubectl apply -f alerts.yaml
输出
prometheusrule.monitoring.coreos.com/high-cpu-alert created
这确认 Prometheus 已成功添加警报规则。
Grafana 中的告警管理
现在让我们了解如何在 Grafana 中管理告警:
编辑 Prometheus 告警规则:
groups:
- name: instance-down
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} is down"
应用告警配置:
$ kubectl apply -f prometheus-rules.yaml
输出
prometheusrule.monitoring.coreos.com/instance-down created
在 Grafana 中设置告警
打开 Grafana:
- 转到 Alerting → Contact Points。
- 创建新的联系点(例如 Email、Slack、PagerDuty)。
- 配置收件人详情。
定义新的告警规则:
- 转到 Alerting → New Alert Rule。
- 选择一个指标查询(例如 node_cpu_seconds_total)。
- 设置条件(例如 CPU 使用率 > 80%)。
- 定义通知策略,将告警与联系点关联。
测试并激活告警:
- 点击 Test Rule 进行验证。
- 保存并启用规则以开始监控。
当条件满足时,告警状态将从 Pending 变为 Firing。此外,当告警触发时,会向配置的联系点发送通知。这确保了 Prometheus 和 Grafana 为监控 Kubernetes 基础设施提供了高效的告警机制。
故障排除常见问题
我们在这里突出了监控中遇到的一些常见问题以及如何排查这些问题。
Prometheus 未抓取指标
- 检查目标是否被正确发现:kubectl get servicemonitors -n monitoring
- 检查 Prometheus 日志:kubectl logs -l app=prometheus -n monitoring
Grafana 仪表板未显示数据
- 验证 Prometheus 数据源连接。
- 检查 PromQL 查询的语法是否正确。
- 检查 Grafana 日志:kubectl logs -l app=grafana -n monitoring
告警未触发
- 确认告警规则已正确加载:kubectl get prometheusrules -n monitoring
- 手动测试告警:kubectl exec -it prometheus-0 -n monitoring -- promtool check rules /etc/prometheus/rules.yaml
Kubernetes 中监控的最佳实践
以下是 Kubernetes 中监控的一些最佳实践:
- 使用仪表板 − 定期查看 Grafana 仪表板以跟踪关键指标。
- 设置告警 − 配置告警以通知异常情况。
- 优化存储 − 确保 Prometheus 保留设置正确配置,以避免过度数据使用。
- 安全访问 − 限制对监控工具的访问,以避免未经授权的访问。
结论
监控和日志记录对于维护健康的 Kubernetes 环境至关重要。Prometheus 和 Grafana 提供了强大的功能,用于收集、分析和可视化指标。通过设置 Prometheus 进行指标收集和 Grafana 进行可视化,我们可以深入洞察集群的健康状况,帮助我们高效检测和解决问题。
通过实施这些工具,我们确保 Kubernetes 工作负载平稳运行,并在问题影响用户之前解决潜在问题。