DBMS - 多级索引
数据检索是数据库管理系统中需要速度和效率的过程。我们实现索引的概念是为了减少搜索时间并加速数据检索。随着数据库规模的增长,高效的索引技术成为减少搜索时间的主要选择。多级索引就是一种这样的索引技术,旨在通过最少的磁盘访问来管理大型数据集。阅读本章以深入了解多级索引的含义、结构以及工作原理。
DBMS 中的多级索引是什么?
在数据库系统中,索引通过组织记录的方式来提高数据检索速度,从而实现更快的搜索。单级索引会创建一个键值列表,指向对应的记录。这个过程可以使用二分搜索。然而,当处理海量数据集时,单级索引由于其规模而变得低效。这时就需要多级索引来提高效率。
为什么使用多级索引?
使用多级索引的主要原因是减少搜索过程中访问的块数。我们知道可以在搜索空间每次步骤中二分,从而应用二分搜索。二分搜索需要大约 log2 (bi) 次块访问,其中 bi 是索引的块数。通过多级索引,我们可以将搜索空间分成更大的段,从而提高搜索速度。这将使搜索时间呈指数级减少。
例如,与其将搜索空间减半,我们可以使用多级索引进一步分割它。这会按照扇出值 (f0) 的因子减少搜索空间,其中扇出值表示一个块中可以容纳的条目数。当扇出值远大于 2 时,搜索过程会显著加快。
多级索引的结构
要理解多级索引的概念,我们必须了解其结构。它被组织成不同的层级,每一层代表一个逐渐变小的索引,直到达到可管理的规模。
其结构包括 −
- 第一级(基础级) − 此级存储主要索引条目。这也被称为基础索引。它包含唯一的键值和指向对应记录的指针。
- 第二级 − 此级作为第一级的主索引。它存储指向第一级块的指针。
- 更高级 − 如果第二级太大无法放入单个块,则会创建额外的层级。这进一步减少了索引规模。
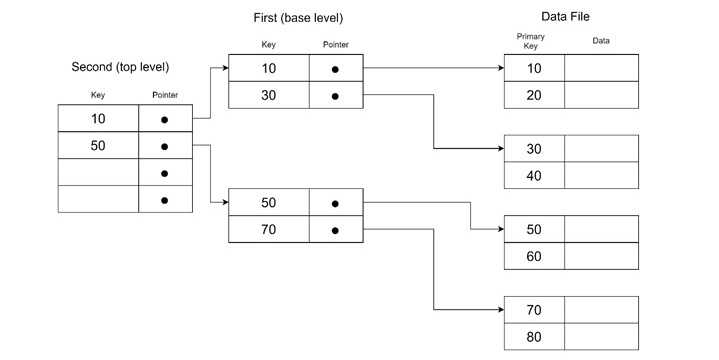
多级索引是如何工作的?
多级索引的每一级都会减少前一级的条目数。这是通过 fan-out 值 (f0) 实现的。该过程持续进行,直到最终级能够放入单个块中,该块被称为顶层。
所需的层数 (t) 计算公式为 −
$$\mathrm{t \:=\: [log_{f_{0}}(r_{1})]}$$
其中,r1 是第一级的条目数,f0 是 fan-out 值。
由此可见,搜索过程涉及从每一级检索一个块,并最终访问数据块。这导致总共 t + 1 次块访问。
多级索引示例
让我们通过一个详细示例来理解多级索引的实际工作方式。
给定数据如下 −
- 阻塞因子 (bfri) − 每个块 68 个条目(也称为 fan-out,fo)。
- 第一级块 (b1) − 442 个块。
步骤 1: 计算第二级
我们计算第二级所需的块数 −
$$\mathrm{b_{2} \:=\: \left[\frac{b_{1}}{f_{0}} \right] \:=\: \left[\frac{442}{68} \right] \:=\: 7}$$
第二级有 7 个块。
步骤 2: 计算第三级
类似地,我们可以计算第三级所需的块数 −
$$\mathrm{b_{3} \:=\: \left[\frac{b_{2}}{f_{0}} \right] \:=\: \left[\frac{7}{68} \right] \:=\: 1}$$
由于第三级能够放入一个块中,它成为索引的顶层。这使得总层数 t = 3。
步骤 3: 记录搜索示例
建立索引后,我们必须从中进行搜索。要使用此多级索引搜索记录,我们需要访问 −
- 每一级的单个块 − 总共三层。
- 文件中的一个数据块 − 包含记录的块。
总块访问次数为: t + 1 = 3 + 1 = 4。这比单级索引有显著改进。使用二分搜索将需要 10 次块访问。
多级索引的类型
根据记录类型和访问模式的不同,多级索引可以以各种形式应用 −
- Primary Index − 建立在已排序的键字段上,使其成为稀疏索引(每个块仅一个索引条目)。
- Clustering Index − 建立在非键字段上,其中多个记录共享相同值。
- Secondary Index − 建立在未排序字段上,需要更多维护但提供灵活性。
Indexed Sequential Access Method (ISAM)
Indexed Sequential Access Method (ISAM) 是多级索引的实际实现。ISAM 常用于较旧的 IBM 系统。它使用两级索引 −
- Cylinder Index − 指向 track-level 块。
- Track Index − 指向圆柱体中的特定 track。
数据插入使用 overflow files 管理。这会在重组期间定期与主文件合并。
多级索引的优势
多级索引提供了以下好处 −
- 更快的搜索 − 减少磁盘访问次数。
- 可扩展性 − 高效处理大型数据集。
- 支持不同索引类型 − 适用于 primary、clustering 和 secondary 索引。
- 均衡访问 − 确保接近均匀的访问时间。
管理多级索引的主要挑战之一是在插入或删除期间。这可能很复杂,因为必须更新所有索引层。当频繁更新发生时,此过程会变得问题重重。
解决方案可以是 dynamic indexing。为了解决这个问题,现代数据库使用 dynamic multi-level 索引,如 B − trees 和 B+ − trees。这些结构通过在插入和删除期间自动重组节点来平衡索引。
结论
在本章中,我们解释了多级索引的概念,并突出了其结构和工作机制。我们了解了通过多个索引级别如何缩小搜索空间。这种技术使得数据检索或搜索变得更快。此外,我们检查了一个详细示例,说明多级索引如何显著减少块访问次数,并使其比单级索引快得多。