机器学习 - 数据分布
在机器学习中,数据分布指的是数据点在数据集中的分布或散布方式。理解数据集中的数据分布非常重要,因为它会对机器学习算法的性能产生重大影响。
数据分布可以通过几个统计量来表征,包括均值、中位数、众数、标准差和方差。这些统计量有助于描述数据的集中趋势、离散程度和形状。
机器学习中一些常见的数据分布类型如下所示 −
正态分布
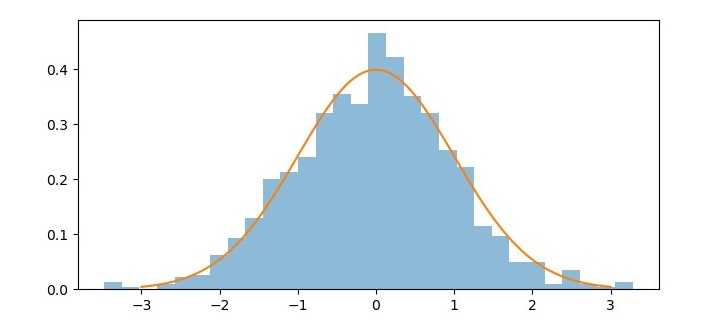
正态分布,也称为高斯分布,是一种连续概率分布,在机器学习和统计学中被广泛使用。它是一种钟形曲线,描述了围绕均值对称的随机变量的概率分布。正态分布有两个参数:均值 (μ) 和标准差 (σ)。
在机器学习中,正态分布常用于建模线性回归和其他统计模型中的误差项分布。它还被用作各种假设检验和置信区间的依据。
正态分布的一个重要性质是经验法则,也称为 68-95-99.7 法则。该法则指出,大约 68% 的观测值落在均值的一个标准差范围内,95% 的观测值落在均值的两个标准差范围内,99.7% 的观测值落在均值的三个标准差范围内。
Python 提供了各种库来处理正态分布。其中一个库是 scipy.stats,它提供了计算概率密度函数 (PDF)、累积分布函数 (CDF)、百分位点函数 (PPF) 以及正态分布随机变量的函数。
示例 - 可视化正态分布
以下是使用 scipy.stats 生成并可视化正态分布的示例 −
import numpy as np from scipy.stats import norm import matplotlib.pyplot as plt # 从正态分布中生成 1000 个随机值的样本 mu = 0 # 均值 sigma = 1 # 标准差 sample = np.random.normal(mu, sigma, 1000) # 计算正态分布的 PDF x = np.linspace(mu - 3*sigma, mu + 3*sigma, 100) pdf = norm.pdf(x, mu, sigma) # 绘制随机样本的直方图和正态分布的 PDF plt.figure(figsize=(7.5, 3.5)) plt.hist(sample, bins=30, density=True, alpha=0.5) plt.plot(x, pdf) plt.show()
在这个示例中,我们首先使用 np.random.normal 从均值为 0、标准差为 1 的正态分布中生成 1000 个随机值的样本。然后使用 norm.pdf 计算正态分布的 PDF,并使用 np.linspace 生成 μ -3σ 到 μ +3σ 之间 100 个均匀间隔的值数组。
最后,我们使用 plt.hist 绘制随机样本的直方图,并使用 plt.plot 叠加正态分布的 PDF。
输出
生成的图表显示了正态分布的钟形曲线以及逼近正态分布的随机样本直方图。
偏态分布
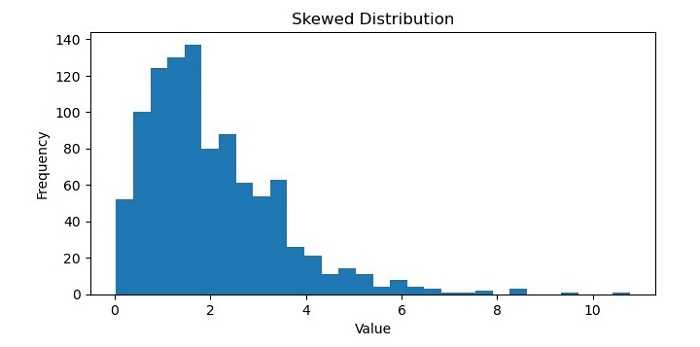
在机器学习中,偏态分布(Skewed Distribution)指的是数据集在其均值(或平均值)周围分布不均匀。在偏态分布中,大多数数据点倾向于聚集在分布的一端,而另一端的数据点较少。
偏态分布有两种类型:左偏(left-skewed)和右偏(right-skewed)。左偏分布,也称为负偏分布,其长尾部位于分布左侧,大多数数据点位于右侧。相反,右偏分布,也称为正偏分布,其长尾部位于分布右侧,大多数数据点位于左侧。
偏态分布可能出现在许多不同类型的数据集中,例如金融数据、社交媒体指标或医疗记录。在机器学习中,正确识别和处理偏态分布非常重要,因为它们会影响某些算法和模型的性能。例如,偏态数据可能导致预测偏差和不准确的结果,在某些情况下需要预处理技术,如归一化或数据转换,来提升模型性能。
示例 - 偏态分布
以下是使用 Python 的 NumPy 和 Matplotlib 库生成并绘制偏态分布的示例 −
import numpy as np
import matplotlib.pyplot as plt
# 使用 NumPy 的随机函数生成偏态分布
data = np.random.gamma(2, 1, 1000)
# 绘制数据的直方图以可视化分布
plt.figure(figsize=(7.5, 3.5))
plt.hist(data, bins=30)
# 为图表添加标签和标题
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Skewed Distribution')
# 显示图表
plt.show()
输出
执行此代码后,您将获得以下图表作为输出 −
均匀分布
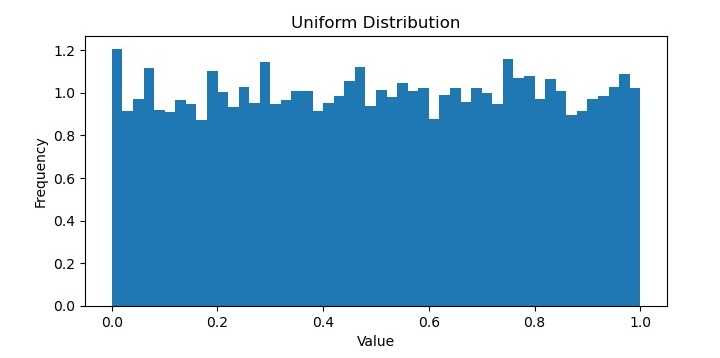
在机器学习中,均匀分布(Uniform Distribution)指的是所有可能结果发生概率相等的概率分布。换句话说,数据集中的每个值被观察到的概率相同,且数据点不会围绕特定值聚集。
均匀分布常被用作与其他分布比较的基准,因为它代表了数据的随机且无偏采样。它在某些应用中也很有用,例如生成随机数或从集合中无偏地选择项目。
在概率论中,连续均匀分布的概率密度函数定义为 −
$$f\left ( x \right )=\left\{\begin{matrix} 1 & for\: a\leq x\leq b \\ 0 & otherwise \\ \end{matrix}\right.$$
其中 a 和 b 分别是分布的最小值和最大值。均匀分布的均值为 $\frac{a+b}{2} $,方差为 $\frac{\left ( b-a \right )^{2}}{12}$
示例 - 均匀分布
在 Python 中,NumPy 库提供了从均匀分布生成随机数的函数,例如 numpy.random.uniform()。这些函数接受分布的最小值和最大值作为参数,可用于生成具有均匀分布的数据集。
以下是使用 Python 的 NumPy 库生成均匀分布的示例 −
import numpy as np
import matplotlib.pyplot as plt
# 在 0 到 1 之间从均匀分布生成 10,000 个随机数
uniform_data = np.random.uniform(low=0, high=1, size=10000)
# 绘制均匀数据的直方图
plt.figure(figsize=(7.5, 3.5))
plt.hist(uniform_data, bins=50, density=True)
# 为图表添加标签和标题
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Uniform Distribution')
# 显示图表
plt.show()
输出
它将生成以下图表作为输出 −
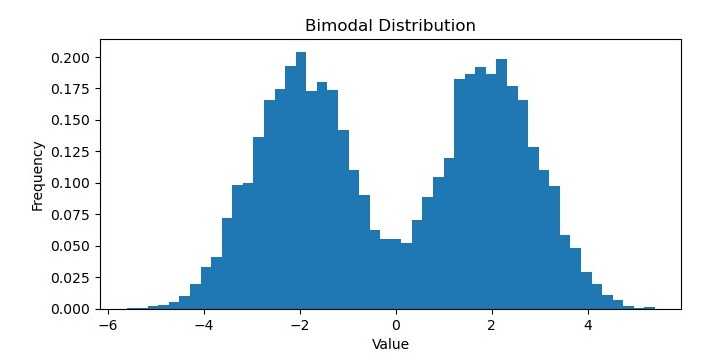
双峰分布
在机器学习中,双峰分布是一种具有两个明显模式或峰值的概率分布。换句话说,该分布有两个数据值最可能出现的高峰区域,中间由一个数据不太可能出现的谷或低谷分开。
双峰分布可能出现在各种类型的数据中,例如生物测量数据、经济指标或社交媒体指标。它们可以代表数据集中的不同子群体,或者不同行为模式或随时间变化的趋势。
可以使用各种统计方法来识别和分析双峰分布,例如直方图、核密度估计或假设检验。在某些情况下,双峰分布可以拟合到特定的概率分布中,例如高斯混合模型,这允许分别建模底层子群体。
示例 - 双峰分布
在 Python 中,NumPy、SciPy 和 Matplotlib 等库提供了生成和可视化双峰分布的函数。
例如,以下代码生成并绘制了一个双峰分布 −
import numpy as np
import matplotlib.pyplot as plt
# 从双峰分布生成 10,000 个随机数
bimodal_data = np.concatenate((np.random.normal(loc=-2, scale=1, size=5000),
np.random.normal(loc=2, scale=1, size=5000)))
# 绘制双峰数据的直方图
plt.figure(figsize=(7.5, 3.5))
plt.hist(bimodal_data, bins=50, density=True)
# 为图表添加标签和标题
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.title('Bimodal Distribution')
# 显示图表
plt.show()
输出
执行此代码后,您将得到以下图表作为输出 −