DBMS - 查询处理中的启发式方法
在查询处理中,我们大量使用启发式方法的概念。查询处理无非是将用户查询转换为高效的执行计划。由于查询的复杂性和数据库中存储的海量数据,直接执行查询可能会很慢且消耗资源。这时,启发式方法就派上用场了。
查询处理中的启发式方法应用规则或策略来优化查询。通过这种方式,我们可以在确保结果正确的同时,使查询更高效。阅读本章以了解启发式方法在查询处理中的作用以及如何在实践中应用它们。
查询处理中的启发式方法
启发式方法是指导原则或经验法则。它们用于简化并改进查询执行。它们专注于减少处理的记录数,并最小化所需的计算量。启发式查询优化不会评估所有可能的查询执行计划,而是使用一组预定义规则对查询进行逻辑转换。
由于以下原因,启发式方法非常重要——
- 效率 − 通过避免不必要的操作来减少处理时间。
- 简单性 − 与基于成本的优化相比,提供更直接的方法。
- 可扩展性 − 通过最小化中间结果,对大型数据集效果良好。
查询树和查询图
在深入探讨启发式规则之前,了解数据库系统中查询的内部表示方式至关重要。有两种常见的表示方式:查询树和查询图。
查询树
查询树是一种树状结构。它是一个层次结构,表示执行查询所需的操作序列。它包括——
- 叶节点 − 表示查询涉及的数据库表。
- 内部节点 − 表示关系操作,如选择(σ)、投影(π)和连接(⋈)。
示例 − 考虑以下查询——
Retrieve the project number, controlling department number, and manager's last name, address, and birthdate for every project located in 'Stafford'.
SQL 查询:
SELECT P.Pnumber, P.Dnum, E.Lname, E.Address, E.Bdate FROM PROJECT AS P, DEPARTMENT AS D, EMPLOYEE AS E WHERE P.Plocation='Stafford' AND P.Dnum=D.Dnumber AND D.Mgr_ssn=E.Ssn;
查询树表示
叶节点 − PROJECT, DEPARTMENT, EMPLOYEE
操作 − 选择(σ)、连接(⋈)和投影(π)
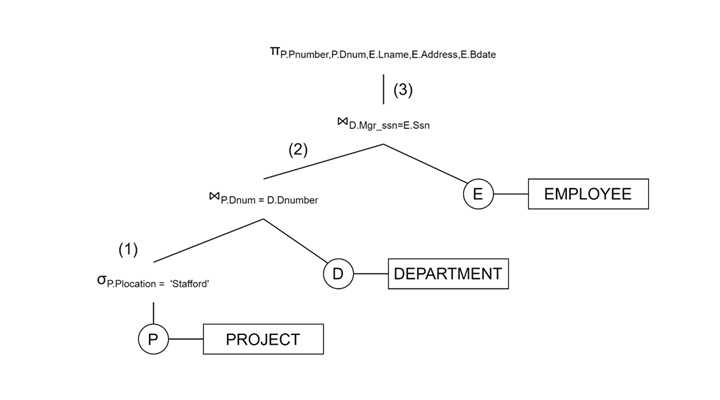
查询图
另一方面,查询图以视觉方式表示关系和操作。在此,关系显示为圆圈,条件表示为连接这些圆圈的边。与查询树不同,查询图不强制特定的执行顺序。
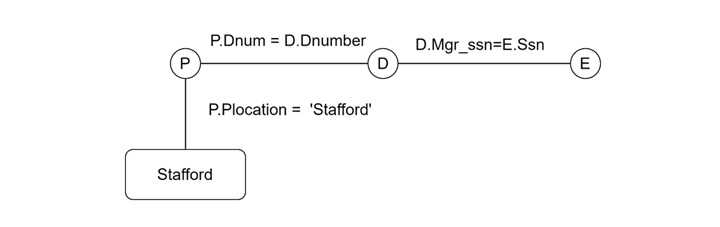
查询优化的启发式规则
启发式查询优化通过应用各种规则,将初始查询树转换为优化的执行计划。让我们通过示例来看看关键的启发式规则。
规则 1:尽早应用选择操作
通过尽早应用选择操作 (σ),可以减少后续阶段处理的记录数。这被称为将选择操作下推到查询树中。例如,考虑以下条件 −
P.Plocation = 'Stafford'
直接将此选择操作应用到 PROJECT 关系上,在连接之前减少不必要的记录。
查询树转换
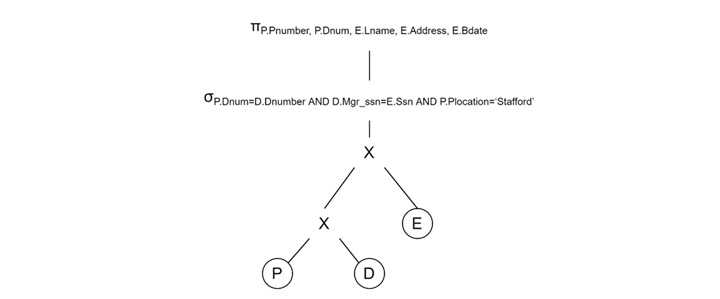
- 之前 − PROJECT ⋈ DEPARTMENT ⋈ EMPLOYEE
- 之后 − σP.Plocation = 'Stafford'(PROJECT) ⋈ DEPARTMENT ⋈ EMPLOYEE
规则 2:分解选择操作(级联)
如果查询有多个选择条件,则将它们分解为单个条件并分别应用。例如,考虑以下条件 −
Bdate > '1957-12-31' AND Pname='Aquarius'
将其分解为两个单独的选择操作 −
σBdate > '1957-12-31' (EMPLOYEE) σPname = 'Aquarius' (PROJECT)
通过这样做,在组合结果之前独立过滤每个表。
规则 3:在选择操作后执行连接
仅在应用选择操作后执行连接。这将最小化参与连接的记录数,使过程更快。考虑以下示例 −
查询 − 查找参与 'Aquarius' 项目的员工。
查询计划 −
Apply selection: σPname = 'Aquarius' (PROJECT)
执行连接 −
PROJECT ⋈ P.Pnumber = W.Pno WORKS_ON ⋈ W.Essn = E.Ssn EMPLOYEE
规则 4:尽早应用投影操作
投影操作 (π) 减少了查询执行中涉及的属性(列)数。现在尽早应用它们以减少内存使用。
示例:仅检索 P.Pnumber、P.Dnum、E.Lname、E.Address 和 E.Bdate。我们不会在整个查询执行过程中拉取多余的列。
规则 5:用连接替换笛卡尔积
除非绝对必要,否则避免使用笛卡尔积。它们资源密集,在实际查询中很少需要。例如,
不是 −
PROJECT × DEPARTMENT × EMPLOYEE
而是使用 −
PROJECT ⋈ P.Dnum=D.Dnumber DEPARTMENT ⋈ D.Mgr_ssn = E.Ssn EMPLOYEE
规则 6:尽可能组合操作
组合操作以最小化中间结果并减少存储需求。
示例 − 如果查询要求查找参与特定项目的员工,则直接检索相关元组,而不是生成中间表。
启发式查询转换示例
让我们看一个完整的示例,以查看启发式规则的实际应用 −
查询 − 查找 1957 年后出生的、参与名为 'Aquarius' 项目的员工的姓氏。
SQL 查询 −
SELECT E.Lname FROM EMPLOYEE AS E, WORKS_ON AS W, PROJECT AS P WHERE P.Pname = 'Aquarius' AND P.Pnumber = W.Pno AND W.Essn = E.Ssn AND E.Bdate > '1957-12-31';
初始查询树(未优化)
从 EMPLOYEE、WORKS_ON 和 PROJECT 的笛卡尔积开始。逐一应用选择条件。
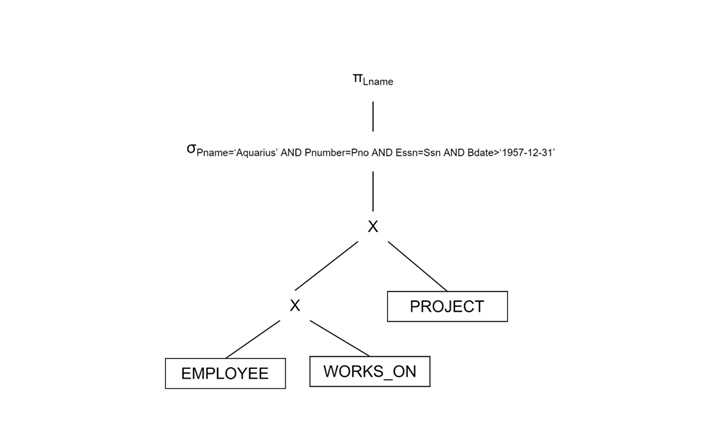
优化后的查询树(使用启发式规则)
首先应用选择操作:
- σPname = 'Aquarius' (PROJECT) 过滤相关项目
- σBdate > '1957-12-31' (EMPLOYEE) 过滤员工
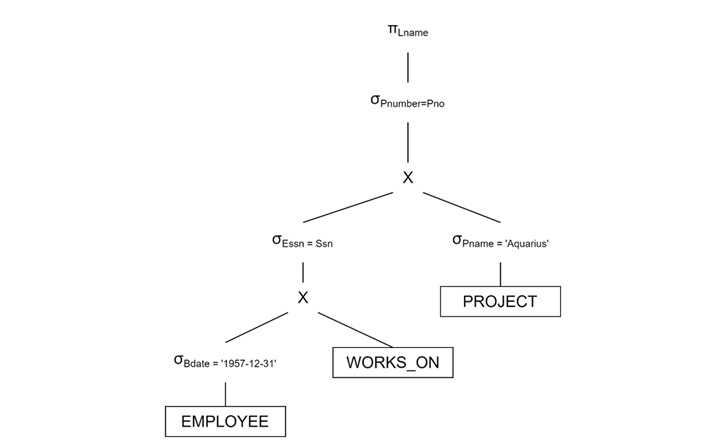
我们可以按以下方式进一步优化 −
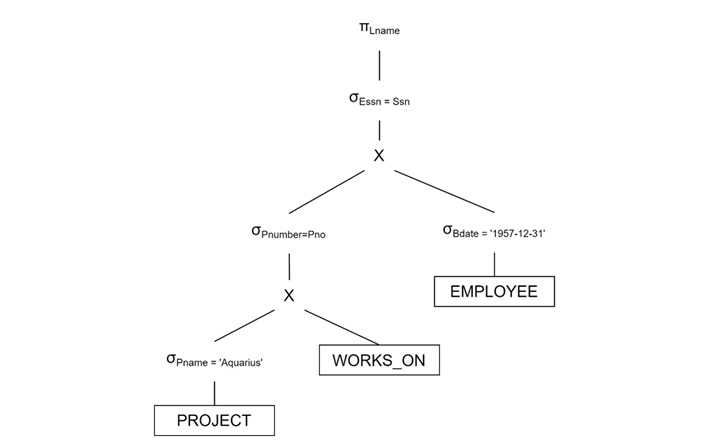
执行连接
- 使用 P.Pnumber = W.Pno 将 PROJECT 与 WORKS_ON 连接。
- 使用 W.Essn = E.Ssn 将结果与 EMPLOYEE 连接。
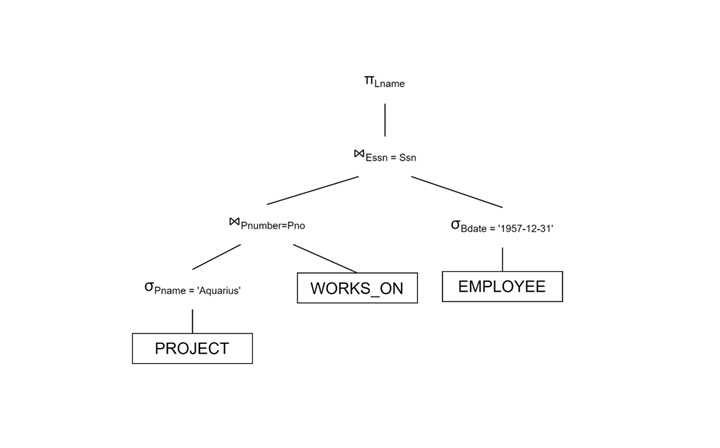
投影结果
通过仅投影所需属性来减少连接开销 −
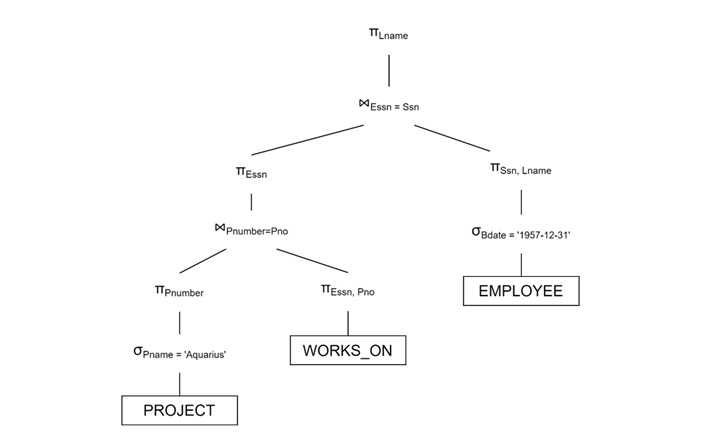
启发式查询处理的好处
我们已经了解到,在查询优化中使用启发式规则有多个好处。它们列在下面 −
- 提高效率 − 减少不必要的数据处理。
- 更快执行 − 通过消除昂贵的操作缩短执行时间。
- 节省内存 − 最小化存储在内存中的中间结果。
- 更简单的查询计划 − 创建易于理解的查询计划。
启发式查询处理的挑战和限制
除了优势和益处之外,也存在一些限制 −
- 并非总是最优 − 启发式是经验法则,可能无法保证最佳执行计划。
- 复杂查询 − 具有多个连接和条件的复杂查询可能仍需要基于成本的优化。
- 自定义能力有限 − 启发式规则是预定义的,在某些场景下限制了灵活性。
结论
在本章中,我们解释了启发式如何简化查询处理。这是通过应用逻辑规则来改善查询执行实现的。我们了解了查询树和查询图的重要性,以及几个关键的启发式规则,例如尽早应用选择操作、高效执行连接并减少中间结果。通过示例和转换,我们探讨了数据库如何优化查询,使其更快、更具可扩展性,并更高效地处理大型数据集。