监督机器学习
什么是监督机器学习?
监督学习,也称为监督机器学习,是一种使用labeled datasets训练模型以预测结果的机器学习类型。Labeled dataset 由输入数据(features)及其对应的输出数据(targets)组成。
监督学习算法的主要目标是在处理多个训练数据实例后,学习输入数据样本与对应输出之间的关联。
监督学习是如何工作的?
在监督机器学习中,模型使用包含输入-输出对的数据集进行训练。
监督学习算法分析数据集,并学习输入数据(features)与正确输出(labels/targets)之间的关系。在训练过程中,模型通过最小化损失函数来估计算法的参数。损失函数衡量模型预测值与实际目标值之间的差异。
模型迭代更新其参数,直到损失/误差被充分最小化。
训练完成后,模型参数达到最优值。模型已学习到输入与目标之间的最优映射/关系。现在,模型可以对新的、未见过的数据进行预测。
监督学习算法的类型
监督机器学习分为两类问题——分类和回归。
1. Classification
基于分类的任务的主要目标是为给定的输入数据预测分类输出标签或响应,例如 true-false、male-female、yes-no 等。如我们所知,分类输出响应表示无序的离散值;因此,每个输出响应将属于特定的类或类别。
一些流行的分类算法包括 decision trees、random forests、support vector machines (SVM)、logistic regression 等。
2. Regression
基于回归的任务的主要目标是为给定的输入数据预测输出标签或响应,这些标签或响应是连续的数值。基本上,回归模型使用输入数据特征(independent variables)及其对应的连续数值输出值(dependent 或 outcome variables),来学习输入与对应输出之间的特定关联。
一些流行的回归算法包括 linear regression、polynomial regression、Lasso regression 等。
监督学习算法
监督学习是训练机器所涉及的重要学习模型之一。本章将详细讨论这一点。
监督学习有多种可用算法。一些广泛使用的监督学习算法如下所示 −
- Linear Regression
- k-Nearest Neighbors
- Decision Trees
- Naive Bayes
- Logistic Regression
- Support Vector Machines
- Random Forest
- Gradient Boosting
让我们详细讨论上述每个监督机器学习算法。
1. Linear Regression
Linear regression 是一种算法,它试图找到输入特征与输出值之间的线性关系,用于预测未来事件。该算法广泛用于股票分析、天气预报等。
2. K-Nearest Neighbors
k-Nearest Neighbors (kNN) 是一种统计技术,可用于解决分类和回归问题。该算法通过数学计算新数据与其他训练数据点之间的最近距离来对新数据进行分类或预测值。
让我们讨论使用 kNN 分类未知对象的情况。考虑如下图像所示的对象分布 −

来源:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
该图显示了三种对象,用红色、蓝色和绿色标记。当你在上述数据集上运行 kNN 分类器时,每种对象的边界将如以下所示 −

来源:
https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm
现在,考虑一个你想要分类为红色、绿色或蓝色的新的未知对象。这在下面的图中显示。

从视觉上看,这个未知数据点属于蓝色对象类。从数学上讲,可以通过测量该未知点与数据集中所有其他点的距离来得出这一结论。这样做后,你会发现它的大多数邻点都是蓝色的。红色和绿色对象之间的平均距离肯定大于蓝色对象之间的平均距离。因此,这个未知对象可以被分类为属于蓝色类。
kNN 算法也可用于回归问题。大多数 ML 库中都提供了现成的 kNN 算法。
3. Decision Trees
Decision tree 是一种树状结构,用于做出决策并分析可能的结果。该算法基于特征将数据分割成子集,其中每个父节点代表内部决策,叶节点代表最终预测。
一个简单的决策树以流程图格式显示如下 −

你将编写代码基于此流程图对输入数据进行分类。该流程图不言自明且简单。在这种情况下,你试图对传入的电子邮件进行分类,以决定何时阅读它。
实际上,决策树可能很大且复杂。有多种算法可用于创建和遍历这些树。作为机器学习爱好者,你需要理解并掌握创建和遍历决策树的技术。
4. Naive Bayes
Naive Bayes 用于创建分类器。假设你想从水果篮中分类不同种类的水果。你可以使用水果的颜色、大小和形状等特征;例如,任何红色、圆形、直径约 10 cm 的水果都可以被视为 Apple。因此,为了训练模型,你将使用这些特征并测试给定特征匹配所需约束的概率。然后,将不同特征的概率组合起来,得出给定水果是 Apple 的概率。Naive Bayes 通常需要少量的训练数据进行分类。
5. Logistic Regression
Logistic regression 是一种统计算法,用于估计事件发生的概率。
查看以下图表。它显示了 XY 平面上的数据点分布。

从图中,我们可以直观地检查红色和绿色点的分离。你可以绘制一条边界线来分离这些点。现在,要分类一个新数据点,你只需确定该点位于线的哪一侧。
6. Support Vector Machines
Support Vector Machines (SVM) 算法通常可用于分类和回归。对于分类任务,该算法创建一个超平面来将数据分离成类。而对于回归,该算法试图拟合一条误差最小的回归线。
查看以下数据分布。这里三个类的数据无法线性分离。边界曲线是非线性的。在这种情况下,求解曲线的方程变得复杂。
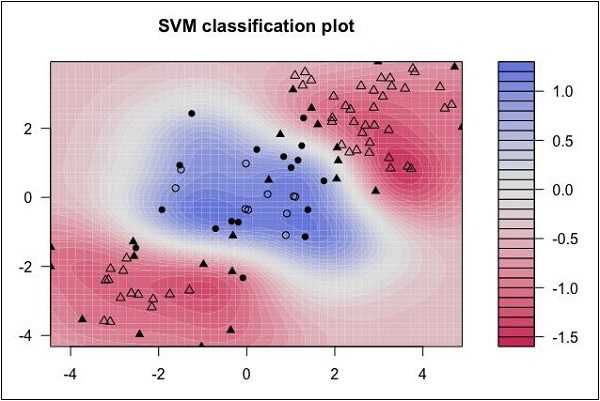
来源: http://uc-r.github.io/svm
Support Vector Machines (SVM) 在这种情况下非常有用,可以确定分离边界。
7. Random Forest
Random forest 也是一种监督学习算法,适用于分类和回归。该算法是多个决策树的组合,通过合并来提高预测准确性。
以下图表说明了 Random Forest 算法的工作原理 −

8. Gradient Boosting
Gradient boosting 将弱学习器(decision trees)组合成一个强模型。它构建新模型来修正前一个模型的错误。该算法的目标是最小化损失函数。它可以高效地用于分类和回归任务。
监督学习的优势
监督学习算法是机器学习模型中最受欢迎的一种。其中一些优势包括:
- 监督学习的目标明确,这提高了预测准确性。
- 使用监督学习训练的模型在预测和分类方面很有效,因为它们使用带标签的数据集。
- 它具有高度的通用性,即可以应用于各种问题,如垃圾邮件检测、股票价格等。
监督学习的缺点
尽管监督学习是最常用的,但它也存在某些挑战。其中一些包括:
- 监督学习需要大量带标签的数据来使模型有效训练。实际中收集如此海量数据非常困难;它既昂贵又耗时。
- 如果测试数据与训练数据不同,监督学习无法准确预测。
- 准确标记数据是复杂的,需要专业知识和努力。
监督学习的应用程序
监督学习模型在各个行业的许多应用程序中被广泛使用,包括以下内容:
- Image recognition − 模型在带标签的图像数据集上进行训练,其中每个图像都关联一个标签。将数据输入模型,使其学习模式和特征。一旦训练完成,模型就可以使用新的、未见过的数据进行测试。这在面部识别和物体检测等应用程序中被广泛使用。
- Predictive analytics − 监督学习算法用于训练带标签的历史数据,使模型学习输入特征与输出之间的模式和关系,以识别趋势并进行准确预测。企业使用这种方法做出数据驱动的决策并提升战略规划。