机器学习 - 直方图
直方图是一种类似于条形图的变量分布表示形式。它显示了变量每个值的出现频率。x 轴表示变量的值范围,y 轴表示每个值的频率或计数。每个条形的高度表示落入该值范围内的数据点数量。
直方图有助于识别数据中的模式,例如偏度、多峰性和异常值。偏度(Skewness)指的是变量分布的不对称程度。多峰性(Modality)指的是分布中的峰值数量。异常值(Outliers)是落在变量典型值范围之外的数据点。
Python 中的直方图实现
Python 提供了多个数据可视化库,例如 Matplotlib、Seaborn、Plotly 和 Bokeh。在下面的示例中,我们将使用 Matplotlib 来实现直方图。
我们将使用 Sklearn 库中的乳腺癌数据集作为本示例。乳腺癌数据集包含乳腺癌细胞特征的信息以及它们是恶性的还是良性的。该数据集有 30 个特征和 569 个样本。
示例 - 基本直方图
首先导入必要的库并加载数据集 −
import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer data = load_breast_cancer()
接下来,我们将创建数据集中的 mean radius 特征的直方图 −
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[:,0], bins=20)
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.show()
在这段代码中,我们使用了 Matplotlib 的 hist() 函数来创建数据集 mean radius 特征的直方图。我们将 bins 设置为 20,将数据范围划分为 20 个区间。我们还使用 xlabel() 和 ylabel() 函数为 x 轴和 y 轴添加了标签。
输出
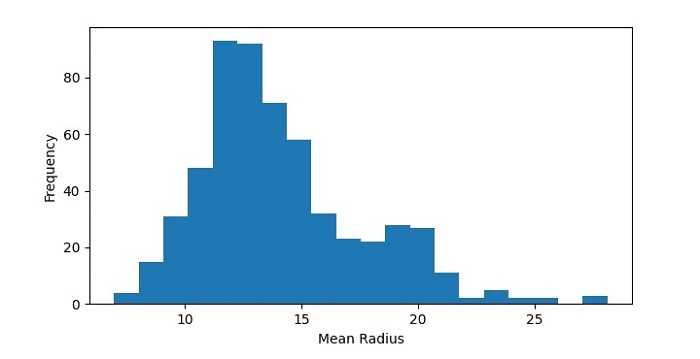
生成的直方图显示了数据集中 mean radius 值的分布。我们可以看到数据大致呈正态分布,在 12-14 附近有一个峰值。
示例 - 多个数据集的直方图
我们还可以创建包含多个数据集的直方图来比较它们的分布。让我们为恶性和良性样本分别创建 mean radius 特征的直方图 −
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[data.target==0,0], bins=20, alpha=0.5, label='Malignant')
plt.hist(data.data[data.target==1,0], bins=20, alpha=0.5, label='Benign')
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.legend()
plt.show()
在这段代码中,我们两次使用 hist() 函数来创建 mean radius 特征的两个直方图,一个用于恶性样本,一个用于良性样本。我们使用 alpha 参数将条形的透明度设置为 0.5,以避免完全重叠。我们还使用 legend() 函数为图表添加了图例。
输出
执行这段代码后,您将得到以下图表作为输出 −
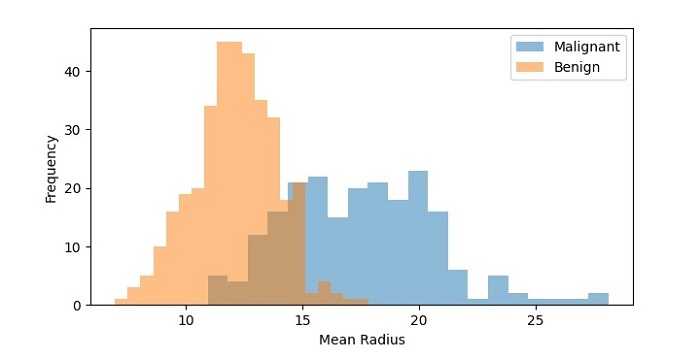
生成的直方图显示了恶性和良性样本的 mean radius 值分布。我们可以看到两种分布不同,恶性样本具有更高 mean radius 值的更高频率。