机器学习 - 混淆矩阵
什么是混淆矩阵?
在机器学习中,confusion matrix 是衡量分类问题性能的最简单方法,其中输出可以是两种或多种类别的类别。它就是一个二维表格,维度分别是“Actual”(实际)和“Predicted”(预测),并且这两个维度都包含“True Positives (TP)”、“True Negatives (TN)”、“False Positives (FP)”、“False Negatives (FN)”,如下图所示 −

以将电子邮件分类为“spam”和“not spam”为例,以便更好地理解。这里,垃圾邮件被标记为“positive”(正类),合法(非垃圾)邮件被标记为 negative(负类)。
与混淆矩阵相关的术语解释如下 −
True Positives (TP) − 当数据点的实际类别和预测类别均为 1 时的情况。分类模型正确预测了数据样本的正类标签。例如,一封“spam”邮件被分类为“spam”。
True Negatives (TN) − 当数据点的实际类别和预测类别均为 0 时的情况。模型正确预测了数据样本的负类标签。例如,一封“not spam”邮件被分类为“not spam”。
False Positives (FP) − 当数据点的实际类别为 0 而预测类别为 1 时的情况。模型错误预测了数据样本的正类标签。例如,一封“not spam”邮件被错误分类为“spam”。这被称为I 型错误。
False Negatives (FN) − 当数据点的实际类别为 1 而预测类别为 0 时的情况。模型错误预测了数据样本的负类标签。例如,一封“spam”邮件被错误分类为“not spam”。这也被称为II 型错误。
我们使用混淆矩阵来找出正确和错误的分类 −
- 正确分类 − TP 和 TN 是正确分类的数据点。
- 错误分类 − FP 和 FN 是错误分类的数据点。
我们可以使用混淆矩阵来计算不同的分类指标,如 accuracy、precision、recall 等。但在讨论这些指标之前,让我们通过一个实际示例来理解如何创建混淆矩阵。
混淆矩阵实际示例
让我们以将电子邮件分类为“spam”或“not spam”为例。这里我们将 spam 电子邮件的 class 表示为 positive (1),而非 spam 电子邮件表示为 negative (0)。因此,电子邮件被分类为以下两种之一 −
- spam (1) − positive class label
- not spam (0) − negative class label
实际类别和预测类别如下 −
| 实际分类 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| 预测分类 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
根据上述结果,让我们找出特定分类属于 TP、TN、FP 或 FN。查看下表 −
| 实际分类 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| 预测分类 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 |
| 结果 | TN | TP | TN | TP | FN | FP | TN | FN | TP | TP |
在上述表格中,当我们将实际分类集与预测分类进行比较时,我们观察到有四种不同类型的结局。首先,true positive (1,1),即实际分类为 positive,预测分类也为 positive。这意味着分类器正确识别了 positive 样本。其次,false negative (1,0),即实际分类为 positive,但预测分类为 negative。分类器将 positive 样本错误识别为 negative。
第三,false positive (0,1),即实际分类为 negative,但预测分类为 positive。negative 样本被错误识别为 positive。第四,true negative (0,0),即实际和预测分类均为 negative。模型正确地将 negative 样本识别为 negative。
让我们找出每个类别中的样本总数。
- TP (True Positive): 4
- FN (False Negative): 2
- FP (False Positive): 1
- TN (True Negative): 3
现在让我们创建如下混淆矩阵 −
| 实际类别 | |||
| Positive (1) | Negative (0) | ||
|
预测类别
|
Positive (1) | 4 (TP) | 1 (FP) |
| Negative (0) | 2 (FN) | 3 (TN) | |
到目前为止,我们已经为上述问题创建了混淆矩阵。让我们从上述矩阵中推断一些含义 −
- 在 10 封电子邮件中,有四封“spam”电子邮件被正确分类为“spam”(TP)。
- 在 10 封电子邮件中,有两封“spam”电子邮件被错误分类为“not spam”(FN)。
- 在 10 封电子邮件中,有一封“not spam”电子邮件被错误分类为“spam”(FP)。
- 在 10 封电子邮件中,有三封“not spam”电子邮件被正确分类为“not spam”(TN)。
- 因此,在 10 封电子邮件中,有七封被正确分类(TP & TN),三封被错误分类(FP & FN)。
基于混淆矩阵的分类指标
我们可以使用混淆矩阵定义许多分类性能指标。我们将考虑上述实际示例,并使用该示例中的值来计算这些指标。其中一些指标如下 −
- Accuracy
- Precision
- Recall 或 Sensitivity
- Specificity
- F1 Score
- Type I Error Rate
- Type II Error Rate
Accuracy
Accuracy 是评估分类模型最常用的指标。它是正确预测总数与所有预测总数之比。从数学上讲,我们可以使用以下公式计算 accuracy −
$$\mathrm{Accuracy = \frac{TP + TN}{TP + FP + FN + TN}}$$
让我们计算 accuracy −
$$\mathrm{Accuracy = \frac{4 + 3}{4 + 1 + 2 + 3}= \frac{7}{10} = 0.7}$$
因此,该模型的分类准确率为 70%。
Precision
Precision 衡量所有预测为阳性的实例中真正例的比例。它计算为真正例数量与真正例和假正例之和的比率。
$$\mathrm{Precision = \frac{TP}{TP + FP}}$$
让我们计算 precision −
$$\mathrm{Precision = \frac{4}{4 + 1} = \frac{4}{5} = 0.8}$$
Recall 或 Sensitivity
Recall(Sensitivity)定义为分类器正确分类的正例数量。我们可以使用以下公式计算它
$$\mathrm{Recall = \frac{TP}{TP + FN}}$$
让我们计算 recall −
$$\mathrm{Recall = \frac{4}{4 + 2} = \frac{4}{6} = 0.666}$$
Specificity
Specificity 与 recall 相反,定义为分类器正确分类的负例数量。我们可以使用以下公式计算它 −
$$\mathrm{Specificity = \frac{TN}{TN + FP}}$$
让我们计算 specificity −
$$\mathrm{Specificity = \frac{3}{3 + 1} = \frac{3}{4} = 0.75}$$
F1 Score
F1 score 是一种平衡度量,它同时考虑了 precision 和 recall。它是 precision 和 recall 的调和平均值。
我们可以使用以下公式计算 F1 score −
$$\mathrm{F1 \: Score = 2 \times \frac{(Precision \times Recall)}{Precision + Recall}}$$
让我们计算 F1 score −
$$\mathrm{F1 \: Score = 2 \times \frac{(0.8 \times 0.667)}{0.8 + 0.667} = 0.727}$$
因此,F1 score 为 0.727。
Type I Error Rate
Type I 错误发生在分类器预测为阳性分类但实际为负类时。Type I 错误率计算为 −
$$\mathrm{Type \: I \: Error \: Rate = \frac{FP}{FP + TN}}$$
$$\mathrm{Type \: I \: Error \: Rate = \frac{1}{1 + 3} = \frac{1}{4} = 0.25}$$
Type II Error Rate
Type II 错误发生在分类器预测为负性但实际为正类时。Type II 错误率可以计算为 −
$$\mathrm{Type \: II \: Error \: Rate = \frac{FN}{FN + TP}}$$
$$\mathrm{Type \: II \: Error \: Rate = \frac{2}{2 + 4} = \frac{2}{6} = 0.333}$$
如何在 Python 中实现混淆矩阵?
要在 Python 中实现混淆矩阵,我们可以使用 scikit-learn 库的 sklearn.metrics 模块中的 confusion_matrix() 函数。
注意: 请注意,confusion_matrix() 函数返回一个 2D 数组,对应于以下混淆矩阵 −
| 预测类别 | |||
| 负类 (0) | 正类 (1) | ||
|
实际类别
|
负类 (0) | 真负类 (TN) | 假正类 (FP) |
| 正类 (1) | 假负类 (FN) | 真正类 (TP) | |
以下是一个使用 confusion_matrix() 函数的简单示例 −
from sklearn.metrics import confusion_matrix # 实际值 y_actual = [0, 1, 0, 1, 1, 0, 0, 1, 1, 1] # 预测值 y_pred = [0, 1, 0, 1, 0, 1, 0, 0, 1, 1] # 混淆矩阵 cm = confusion_matrix(y_actual, y_pred) print(cm)
在这个示例中,我们有两个数组:y_actual 包含目标变量的实际值,y_pred 包含目标变量的预测值。然后我们调用 confusion_matrix() 函数,将 y_actual 和 y_pred 作为参数传入。该函数返回一个表示混淆矩阵的 2D 数组。
上述代码的 输出 将如下所示 −
[[3 1] [2 4]]
将上述结果与我们上面创建的混淆矩阵进行比较。
- 真负类 (TN): 3
- 假正类 (FP): 1
- 假负类 (FN): 2
- 真正类 (TP): 4
我们还可以使用 heatmap 来可视化混淆矩阵。以下是如何使用 seaborn 库的 heatmap() 函数实现的方法
import seaborn as sns # 将混淆矩阵绘制为热力图 sns.heatmap(cm, annot=True, cmap='summer')
输出
这将生成一个显示混淆矩阵的热力图 −
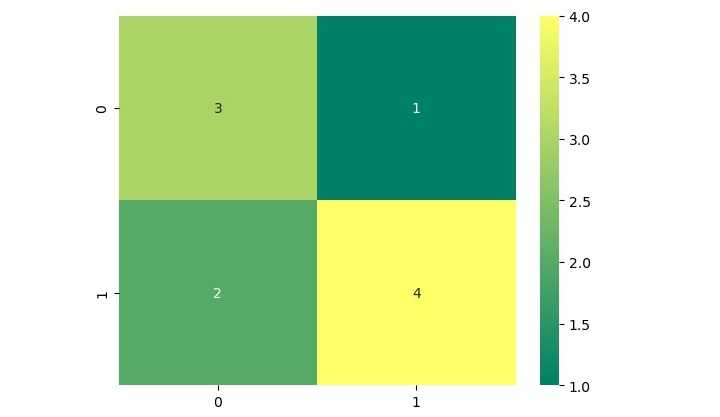
在这个热力图中,x 轴表示预测值,y 轴表示实际值。热力图中每个方块的颜色表示落入每个类别的样本数量。