编译器设计 - 错误恢复
解析器应该能够检测并报告程序中的任何错误。预期的是,当遇到错误时,解析器能够处理它并继续解析其余输入。大多数情况下,解析器需要检查错误,但错误可能在编译过程的各个阶段被遇到。程序在各个阶段可能存在以下几种错误:
词法:某些标识符名称输入错误
语法:缺少分号或括号不匹配
语义:不兼容的值赋值
逻辑:代码不可达、无限循环
解析器中可以实现四种常见的错误恢复策略来处理代码中的错误。
Panic mode
当解析器在语句的任何位置遇到错误时,它会忽略语句的其余部分,不处理从错误输入到分隔符(如分号)的输入。这是错误恢复的最简单方法,而且它能防止解析器陷入无限循环。
Statement mode
当解析器遇到错误时,它会尝试采取纠正措施,以便语句的其余输入允许解析器继续解析。例如,插入缺少的分号、将逗号替换为分号等。解析器设计者在这里需要小心,因为一个错误的纠正可能会导致无限循环。
Error productions
编译器设计者已知一些常见的代码错误。此外,设计者可以创建扩充文法,用于生成错误构造的产生式,当遇到这些错误时使用。
Global correction
解析器将手头的程序视为一个整体,试图弄清楚程序的预期功能,并寻找最接近的无错匹配。当输入错误语句 X 时,它会为某个最接近的无错语句 Y 创建解析树。这可能允许解析器对源代码进行最小更改,但由于该策略的复杂性(时间和空间),尚未在实践中实现。
Abstract Syntax Trees
解析树表示对编译器来说不易解析,因为它们包含了比实际需要更多的细节。以以下解析树为例:
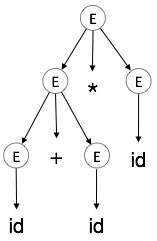
仔细观察,我们会发现大多数叶节点都是其父节点的单一子节点。在此之前,可以消除这些信息,然后将其输入到下一阶段。通过隐藏多余信息,我们可以得到如下所示的树:
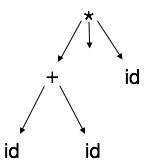
抽象语法树可以表示为:
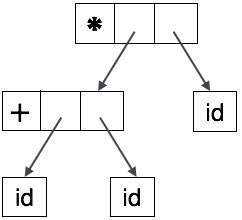
AST 是编译器中重要的数据结构,包含最少的不必要信息。AST 比解析树更紧凑,便于编译器使用。