SciPy - 曲线拟合
曲线拟合 是构建一个数学函数的过程,该函数最接近一组数据点。在 SciPy 中,来自 scipy.optimize 模块的 curve_fit() 函数常用于将给定的模型(通常是非线性的)拟合到数据上。其目标是找到模型的最优参数,以最小化数据与模型预测值之间的差异,即残差。
曲线拟合的工作原理?
众所周知,曲线拟合 是找到一条最能描述一组数据点之间关系的曲线的过程。详细来说,其工作原理如下 −
- 数据点: 数据包括自变量 和因变量 。这些点代表观测值或测量值。
- 模型选择: 选择一个数学模型,如线性、多项式、指数等,来表示潜在趋势。该模型具有需要确定以拟合数据的参数。
- 目标: 目标是找到模型的参数,使得曲线最小化预测值 model() 与观测数据 之间的差异,即误差。
- 误差计算: 可以使用损失函数来计算误差,通常是平方误差和 (SSE),公式如下 −
SSE = (observed - model)2
这确保较大的差异对总误差的贡献更大。
- 优化: 应用优化技术(如最小二乘法)来调整模型参数,以最小化误差。
- 曲线拟合工具: SciPy 的 curve_fit() 函数被广泛使用。它接受模型函数、数据以及参数的初始猜测,并返回拟合数据的参数。
曲线拟合的类型
根据数据的性质和使用的模型,有多种曲线拟合技术。这些技术可以从简单的线性拟合到更复杂的非线性模型。以下是 SciPy 中常用的主要曲线拟合类型 −
| 曲线拟合类型 | 定义 | 模型方程 | 使用场景 |
|---|---|---|---|
| 线性 | 一种将直线拟合到数据点的方法,显示变量之间恒定的变化率。 | y = ax + b | 当关系近似线性时。 |
| 多项式 | 使用多项式方程拟合数据点的方法,能够捕捉更复杂的关系。 | y = an xn + an-1 xn-1 + ... + a0 | 用于平滑的非线性关系(如二次、三次)。 |
| 指数 | 当数据显示指数增长或衰减时使用的拟合方法,常見于自然现象。 | y = a ebx + c | 指数增长或衰减的数据。 |
| 对数 | 一种建模变化率随时间减少的关系的拟合方法。 | y = a log(x) + b | 当自变量增加时增长放缓。 |
| 幂律 | 一种建模一个变量作为另一个变量幂次变化的数据的方法,常用于尺度不变现象。 | y = axb | 当一个变量作为另一个变量的幂次变化时。 |
| S 形(Logistic) | 一种拟合 S 形曲线的方法,常用于趋于饱和的增长过程。 | y = a / (1 + e-b(x - c)) | 用于增长或饱和模型中的 S 形曲线。 |
| 高斯 | 一种建模钟形分布数据的方法,典型用于统计分析。 | y = a e-(x - b)2 / (2c2) | 钟形数据分布(正态分布)。 |
| 有理函数 | 一种使用多项式方程比率拟合的方法,用于描述变量之间更复杂的关系。 | y = (an xn + ... + a0) / (bm xm + ... + b0) | 需要多项式比率的更复杂关系。 |
理解结果
理解曲线拟合的结果涉及解释拟合过程的输出,并评估模型描述数据的好坏程度。
- 拟合参数: 估计的参数使实际数据与模型函数预测值之间的差异最小化。
- 协方差矩阵: 协方差矩阵提供了参数估计准确性的洞察。对角元素表示每个参数的方差,帮助我们理解拟合值的置信度。
曲线拟合 vs 插值
曲线拟合 专注于为预测目的建模变量之间的关系,而插值则关注在已知数据点之间估计值,确保在观测范围内具有精度。这两种技术之间的选择取决于分析目标和数据的性质。
以下是曲线拟合和插值的比较 −
| 方面 | 曲线拟合 | 插值 |
|---|---|---|
| 定义 | 找到一条最能代表数据点之间关系的曲线。 | 在已知数据点之间估计值。 |
| 目的 | 建模潜在趋势以进行预测和洞察。 | 在已知范围内提供精确估计。 |
| 方法 | 最小二乘拟合、多项式拟合、回归分析。 | 线性插值、多项式插值、样条插值。 |
| 数学方法 | 最小化拟合曲线与数据点之间的误差。 | 构造新点,确保函数通过已知数据。 |
| 适用性 | 用于理解关系和泛化(例如,回归)。 | 用于精确值估计(例如,数值方法)。 |
| 外推 | 允许超出观测数据范围的外推,但需谨慎。 | 不涉及外推,估计仅限于已知数据范围。 |
| 输出 | 一条平滑曲线,可能不通过所有数据点。 | 一条精确通过所有已知数据点的曲线。 |
SciPy 的曲线拟合函数
我们可以使用函数 scipy.optimize.curve_fit() 在 SciPy 中执行曲线拟合。
| 序号 | 函数 & 描述 |
|---|---|
| 1 | scipy.optimize.curve_fit() 使用非线性最小二乘法将函数拟合到数据。允许用户定义自定义模型进行拟合,并返回最能描述数据的优化参数。 |
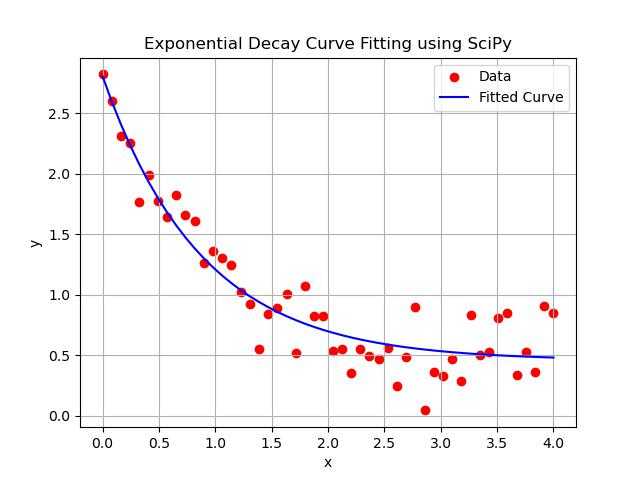
以下示例演示了如何使用 curve_fit() 函数将指数衰减函数拟合到数据 −
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit
# 定义模型函数(指数衰减)
def model_func(x, a, b, c):
return a * np.exp(-b * x) + c
# 生成合成数据(带噪声的指数衰减)
x_data = np.linspace(0, 4, 50)
y_data = model_func(x_data, 2.5, 1.3, 0.5) + np.random.normal(0, 0.2, size=x_data.shape)
# 执行曲线拟合
# 参数 a, b, c 的初始猜测是可选的,但可以加速收敛
params, params_covariance = curve_fit(model_func, x_data, y_data, p0=[2, 1, 0])
# 从拟合曲线生成数据
y_fitted = model_func(x_data, *params)
# 绘制原始带噪声数据和拟合曲线
plt.scatter(x_data, y_data, label='Data', color='red')
plt.plot(x_data, y_fitted, label='Fitted Curve', color='blue')
# 添加标签和标题
plt.title('Exponential Decay Curve Fitting using SciPy')
plt.xlabel('x')
plt.ylabel('y')
plt.legend()
plt.grid(True)
plt.show()
# 打印拟合参数
print(f"Fitted parameters: a = {params[0]}, b = {params[1]}, c = {params[2]}")
以下是 SciPy 中曲线拟合的输出 −