数据结构 - 排序技术
排序是指将数据按照特定格式排列。排序算法指定了将数据按特定顺序排列的方式。最常见的顺序是数值顺序或字典顺序。
排序的重要性在于,如果数据以排序方式存储,数据搜索可以被优化到非常高的水平。排序还用于以更易读的格式表示数据。以下是一些现实生活场景中排序的示例 −
电话簿 − 电话簿按人们的姓名排序存储电话号码,以便轻松搜索姓名。
字典 − 字典按字母顺序存储单词,以便轻松搜索任何单词。
原地排序和非原地排序
排序算法可能需要一些额外的空间用于比较和临时存储少量数据元素。这些算法不需要任何额外空间,排序被认为是在原地发生的,例如在数组本身内部。这被称为原地排序。Bubble sort 是原地排序的一个示例。
然而,在某些排序算法中,程序需要等于或大于被排序元素的空间。使用相等或更多空间的排序被称为非原地排序。Merge-sort 是非原地排序的一个示例。
稳定排序和非稳定排序
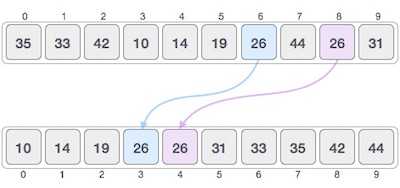
如果一个排序算法在排序内容后,不改变相同内容出现的序列,则称为稳定排序。
如果一个排序算法在排序内容后,改变了相同内容出现的序列,则称为不稳定排序。
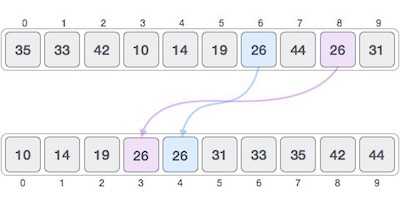
当我们希望保持原始元素的序列时,例如在元组中,算法的稳定性就很重要了。
自适应排序算法和非自适应排序算法
如果一个排序算法利用了待排序列表中已经“排序”的元素,则称为自适应。它在排序过程中,如果源列表中有些元素已经排序,自适应算法会考虑这一点,并尽量不重新排序它们。
非自适应算法不考虑已经排序的元素。它试图强制每个元素都重新排序,以确认它们的排序状态。
重要术语
在讨论排序技术时,通常会使用一些术语,以下是对这些术语的简要介绍 −
递增顺序
如果一个值序列中每个后续元素都大于前一个元素,则称该序列处于递增顺序。例如,1, 3, 4, 6, 8, 9 处于递增顺序,因为每个后续元素都大于前一个元素。
递减顺序
如果一个值序列中每个后续元素都小于当前元素,则称该序列处于递减顺序。例如,9, 8, 6, 4, 3, 1 处于递减顺序,因为每个后续元素都小于前一个元素。
非递增顺序
如果一个值序列中每个后续元素小于或等于序列中前一个元素,则称该序列处于非递增顺序。这种顺序出现在序列包含重复值时。例如,9, 8, 6, 3, 3, 1 处于非递增顺序,因为每个后续元素小于或等于(3 的情况)但不大于任何前一个元素。
非递减顺序
如果一个值序列中每个后续元素大于或等于序列中前一个元素,则称该序列处于非递减顺序。这种顺序出现在序列包含重复值时。例如,1, 3, 3, 6, 8, 9 处于非递减顺序,因为每个后续元素大于或等于(3 的情况)但不小于前一个元素。
有多种排序技术可用于对各种数据结构的內容进行排序。以下是一些排序技术 −
Bubble Sort
Insertion Sort
Selection Sort
Merge Sort
Shell Sort
Heap Sort
Bucket Sort Algorithm
Counting Sort Algorithm
Radix Sort Algorithm
Quick Sort