Amazon Web Services - Data Pipeline
AWS Data Pipeline 是一个 web 服务,旨在帮助用户更容易地将分布在多个 AWS 服务中的数据集成起来,并从单一位置对其进行分析。
使用 AWS Data Pipeline,可以从源头访问数据,进行处理,然后将结果高效传输到相应的 AWS 服务。
如何设置 Data Pipeline?
以下是设置 data pipeline 的步骤 −
步骤 1 − 使用以下步骤创建 Pipeline。
登录 AWS 账户。
使用此链接打开 AWS Data Pipeline 控制台 − https://console.aws.amazon.com/datapipeline/
在导航栏中选择区域。
点击 Create New Pipeline 按钮。
在相应字段中填写所需详细信息。
在 Source 字段中,选择 Build using a template,然后选择此模板 − Getting Started using ShellCommandActivity。
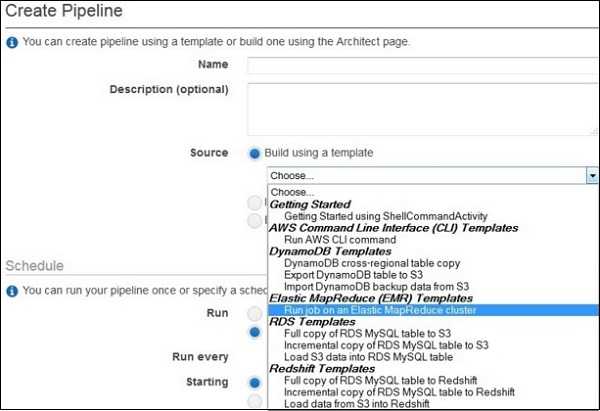
选择模板后,Parameters 部分才会打开。将 S3 input folder 和 Shell command to run 保留为默认值。点击 S3 output folder 旁边的文件夹图标,并选择 bucket。
在 Schedule 中,将值保留为默认。
在 Pipeline Configuration 中,将 logging 保留为启用状态。点击 S3 location for logs 下方的文件夹图标,并选择 bucket。
在 Security/Access 中,将 IAM roles 值保留为默认。
点击 Activate 按钮。
如何删除 Pipeline?
删除 pipeline 也将删除所有关联的对象。
步骤 1 − 从 pipeline 列表中选择 pipeline。
步骤 2 − 点击 Actions 按钮,然后选择 Delete。
步骤 3 − 确认提示窗口打开。点击 Delete。
AWS Data Pipeline 的特性
简单且成本效益高 − 其拖放功能使得在控制台上创建 pipeline 变得容易。其可视化 pipeline 创建器提供了一个 pipeline 模板库。这些模板使得创建处理日志文件、将数据归档到 Amazon S3 等任务的 pipeline 变得更容易。
可靠 − 其基础设施设计用于容错执行活动。如果活动逻辑或数据源发生故障,AWS Data Pipeline 会自动重试该活动。如果故障持续,则会发送故障通知。我们甚至可以为成功运行、故障、活动延迟等情况配置这些通知警报。
灵活 − AWS Data Pipeline 提供各种功能,如调度、跟踪、错误处理等。它可以配置为执行诸如运行 Amazon EMR 作业、直接针对数据库执行 SQL 查询、在 Amazon EC2 上运行自定义应用程序等操作。