Tries 数据结构

- Trie 中的基本操作
- 插入操作
- 删除操作
- 搜索操作
Trie 是一种多路搜索树,主要用于从字符串或字符串集合中检索特定的键。它以有序高效的方式存储数据,因为它为字母表中的每个字母使用指针。
Trie 数据结构基于字符串的公共前缀工作。根节点可以根据集合中字符串的数量拥有任意数量的子节点。Trie 的根节点除了指向其子节点的指针外,不包含任何值。
Trie 数据结构有三种类型 —
标准 Trie
压缩 Trie
后缀 Trie
Trie 的实际应用包括 — 自动更正、文本预测、情感分析和数据科学。
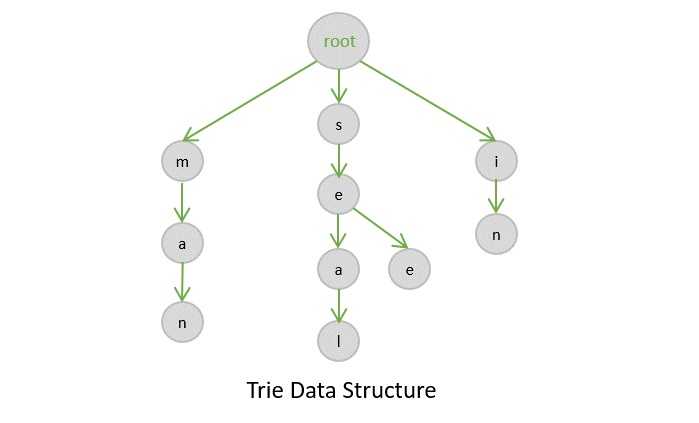
Trie 中的基本操作
Trie 数据结构也执行树数据结构执行的相同操作。它们是 —
插入
删除
搜索
插入操作
trie 中的插入操作是一种简单的方法。trie 中的根节点不存储任何值,插入从根节点的直接子节点开始,这些子节点充当其子节点的键。然而,我们观察到 trie 中的每个节点代表输入字符串中的单个字符。因此,字符一个一个地添加到 trie 中,而 trie 中的链接充当指向下一级节点的指针。
示例
以下是此操作在各种编程语言中的实现 −
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define ALPHABET_SIZE 26
struct TrieNode {
struct TrieNode* children[ALPHABET_SIZE];
int isEndOfWord;
};
struct Trie {
struct TrieNode* root;
};
struct TrieNode* createNode() {
struct TrieNode* node = (struct TrieNode*)malloc(sizeof(struct TrieNode));
node->isEndOfWord = 0;
for (int i = 0; i < ALPHABET_SIZE; i++) {
node->children[i] = NULL;
}
return node;
}
void insert(struct Trie* trie, const char* key) {
struct TrieNode* curr = trie->root;
for (int i = 0; i < strlen(key); i++) {
int index = key[i] - 'a';
if (curr->children[index] == NULL) {
curr->children[index] = createNode();
}
curr = curr->children[index];
}
curr->isEndOfWord = 1;
}
void printWords(struct TrieNode* node, char* prefix) {
if (node->isEndOfWord) {
printf("%s\n", prefix);
}
for (int i = 0; i < ALPHABET_SIZE; i++) {
if (node->children[i] != NULL) {
char* newPrefix = (char*)malloc(strlen(prefix) + 2);
strcpy(newPrefix, prefix);
newPrefix[strlen(prefix)] = 'A' + i;
newPrefix[strlen(prefix) + 1] = '\0';
printWords(node->children[i], newPrefix);
free(newPrefix);
}
}
}
int main() {
struct Trie car;
car.root = createNode();
insert(&car, "lamborghini");
insert(&car, "mercedes-Benz");
insert(&car, "land Rover");
insert(&car, "maruti Suzuki");
printf("Trie elements are:\n");
printWords(car.root, "");
return 0;
}
输出
Trie elements are: LAMBORGHINI LANDNOVER MARUTIOUZUKI MERCEZENZ
#include <iostream>
#include <unordered_map>
#include <string>
class TrieNode {
public:
std::unordered_map<char, TrieNode*> children;
bool isEndOfWord;
TrieNode() {
isEndOfWord = false;
}
};
class Trie {
private:
TrieNode* root;
public:
Trie() {
root = new TrieNode();
}
void insert(std::string word) {
TrieNode* curr = root;
for (char ch : word) {
if (curr->children.find(ch) == curr->children.end()) {
curr->children[ch] = new TrieNode();
}
curr = curr->children[ch];
}
curr->isEndOfWord = true;
}
TrieNode* getRoot() {
return root;
}
};
void printWords(TrieNode* node, std::string prefix) {
if (node->isEndOfWord) {
std::cout << prefix << std::endl;
}
for (auto entry : node->children) {
printWords(entry.second, prefix + entry.first);
}
}
int main() {
Trie car;
car.insert("Lamborghini");
car.insert("Mercedes-Benz");
car.insert("Land Rover");
car.insert("Maruti Suzuki");
std::cout << "Tries elements are: " << std::endl;
printWords(car.getRoot(), "");
return 0;
}
输出
Tries elements are: Maruti Suzuki Mercedes-Benz Land Rover Lamborghini
import java.util.HashMap;
import java.util.Map;
class TrieNode {
Map<Character, TrieNode> children;
boolean isEndOfWord;
TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
}
class Trie {
private TrieNode root;
Trie() {
root = new TrieNode();
}
void insert(String word) {
TrieNode curr = root;
for (char ch : word.toCharArray()) {
curr.children.putIfAbsent(ch, new TrieNode());
curr = curr.children.get(ch);
}
curr.isEndOfWord = true;
}
TrieNode getRoot() {
return root;
}
}
public class Main {
public static void printWords(TrieNode node, String prefix) {
if (node.isEndOfWord) {
System.out.println(prefix);
}
for (Map.Entry<Character, TrieNode> entry : node.children.entrySet()) {
printWords(entry.getValue(), prefix + entry.getKey());
}
}
public static void main(String[] args) {
Trie car = new Trie();
// Inserting the elements
car.insert("Lamborghini");
car.insert("Mercedes-Benz");
car.insert("Land Rover");
car.insert("Maruti Suzuki");
// Print the inserted objects
System.out.print("Tries elements are: \n");
printWords(car.getRoot(), ""); // Access root using the public method
}
}
输出
Tries elements are: Lamborghini Land Rover Maruti Suzuki Mercedes-Benz
class TrieNode:
def __init__(self):
self.children = {}
self.isEndOfWord = False
class Trie:
def __init__(self):
self.root = TrieNode()
def insert(self, word):
curr = self.root
for ch in word:
curr.children.setdefault(ch, TrieNode())
curr = curr.children[ch]
curr.isEndOfWord = True
def getRoot(self):
return self.root
def printWords(node, prefix):
if node.isEndOfWord:
print(prefix)
for ch, child in node.children.items():
printWords(child, prefix + ch)
if __name__ == '__main__':
car = Trie()
# Inserting the elements
car.insert("Lamborghini")
car.insert("Mercedes-Benz")
car.insert("Land Rover")
car.insert("Maruti Suzuki")
# Print the inserted objects
print("Tries elements are: ")
printWords(car.getRoot(), "")
输出
Tries elements are: Lamborghini Land Rover Mercedes-Benz Maruti Suzuki
删除操作
trie 中的删除操作采用自底向上的方法进行。在 trie 中搜索元素并删除,如果找到的话。然而,在执行删除操作时,需要注意一些特殊情况。
情况 1 − 键是唯一的 − 在这种情况下,从节点中删除整个键路径。(唯一键表明没有其他路径从该路径分支出)。
情况 2 − 键不是唯一的 − 更新叶子节点。例如,如果要删除的键是 see,但它是另一个键 seethe 的前缀;我们删除 see,并将 t、h 和 e 的布尔值更改为 false。
情况 3 − 要删除的键已经有一个前缀 − 删除前缀之前的值,前缀保留在树中。例如,如果要删除的键是 heart,但存在另一个键 he;因此我们删除 a、r 和 t,直到只剩下 he。
示例
以下是此操作在各种编程语言中的实现 −
//C code for Deletion Operation of tries Algorithm
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include <string.h>
//Define size 26
#define ALPHABET_SIZE 26
struct TrieNode {
struct TrieNode* children[ALPHABET_SIZE];
bool isEndOfWord;
};
struct Trie {
struct TrieNode* root;
};
struct TrieNode* createNode() {
struct TrieNode* node = (struct TrieNode*)malloc(sizeof(struct TrieNode));
node->isEndOfWord = false;
for (int i = 0; i < ALPHABET_SIZE; i++) {
node->children[i] = NULL;
}
return node;
}
void insert(struct Trie* trie, const char* key) {
struct TrieNode* curr = trie->root;
for (int i = 0; i < strlen(key); i++) {
int index = key[i] - 'a';
if (curr->children[index] == NULL) {
curr->children[index] = createNode();
}
curr = curr->搜索操作
在 trie 中进行搜索是一种相当直接的方法。我们只能根据键节点(插入操作开始的节点)向下移动 trie 的层级。搜索一直进行到路径末尾。如果找到元素,则搜索成功;否则,搜索失败。
示例
以下是此操作在各种编程语言中的实现 −
C
C++
Java
Python
//C 程序,用于 trie 算法的搜索操作
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define ALPHABET_SIZE 26
struct TrieNode {
struct TrieNode* children[ALPHABET_SIZE];
bool isEndOfWord;
};
struct TrieNode* createNode() {
struct TrieNode* node = (struct TrieNode*)malloc(sizeof(struct TrieNode));
node->isEndOfWord = false;
for (int i = 0; i < ALPHABET_SIZE; i++) {
node->children[i] = NULL;
}
return node;
}
void insert(struct TrieNode* root, char* word) {
struct TrieNode* curr = root;
for (int i = 0; word[i] != '\0'; i++) {
int index = word[i] - 'a';
if (curr->children[index] == NULL) {
curr->children[index] = createNode();
}
curr = curr->children[index];
}
curr->isEndOfWord = true;
}
bool search(struct TrieNode* root, char* word) {
struct TrieNode* curr = root;
for (int i = 0;