数据结构 - 搜索算法

- 数据结构中的搜索算法
- 评估搜索算法
在前一节中,我们讨论了各种排序技术和它们的使用场景。然而,进行排序的主要目的是以有序的方式排列数据,从而更容易在已排序的数据中搜索任意元素。
搜索是在大量数据中查找特定记录的过程,该记录可以是单个元素或一小块数据。数据可以以各种形式存在:arrays、linked lists、trees、heaps 和 graphs 等。随着当今数据量的不断增加,有多种技术可以执行搜索操作。
数据结构中的搜索算法
可以在数据结构上应用各种搜索技术来检索特定数据。只有当搜索操作返回所需元素或数据时,才认为搜索操作成功;否则,该搜索方法就是不成功的。
这些搜索技术分为两大类,它们是——
顺序搜索
区间搜索
顺序搜索
顾名思义,顺序搜索操作会按顺序遍历数据中的每个元素来查找所需数据。此类搜索不需要数据处于排序状态。
示例 − Linear Search
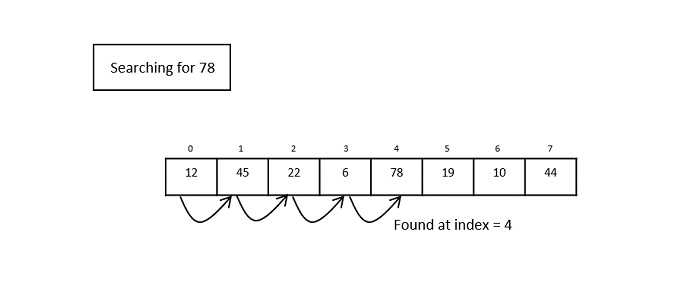
图 1: Linear Search 操作
区间搜索
与顺序搜索不同,区间搜索操作要求数据处于排序状态。此方法通常以区间方式搜索数据;可以通过将数据分成多个子部分或通过索引跳跃来搜索元素。
示例 − Binary Search、Jump Search 等。
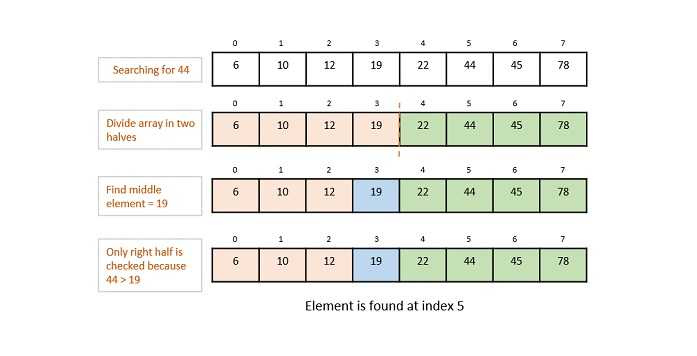
图 2: Binary Search 操作
评估搜索算法
通常,并非所有搜索技术都适用于所有类型的数据结构。在某些情况下,顺序搜索更可取,而在其他情况下,区间搜索更可取。对这些搜索技术的评估是通过检查每种搜索方法在特定输入上的运行时间来完成的。
这正是渐近记号发挥作用的地方。要了解更多关于 Asymptotic Notations 的信息,请点击这里。
简要说明,程序运行的时间复杂度有三种不同的情况,它们是——
最佳情况
平均情况
最坏情况
我们主要关注最佳情况和最坏情况的时间复杂度,因为平均情况难以计算。而且由于运行时间取决于提供给程序的输入量,最坏情况时间复杂度最能描述任何算法的性能。
例如,linear search 的最佳情况时间复杂度为 O(1),此时在第一次迭代中就找到了所需元素;而最坏情况时间复杂度为 O(n),此时程序遍历了所有元素仍未找到元素。这被标记为不成功的搜索。因此,linear search 的实际时间复杂度被视为 O(n),其中 n 是输入数据结构中元素的数量。
许多类型的搜索方法用于在各种数据结构中搜索数据条目。其中一些包括——
Linear Search
Binary Search
Interpolation Search
Jump Search
Hash Table
Exponential Search
Sublist search
Fibonacci Search
Ubiquitous Binary Search
我们将在后续章节中详细介绍这些搜索方法。