编译器 - 中间代码生成
源代码可以直接翻译成目标机器代码,那么为什么我们还需要将源代码翻译成中间代码,然后再翻译成目标代码呢?让我们来看看为什么需要中间代码的原因。
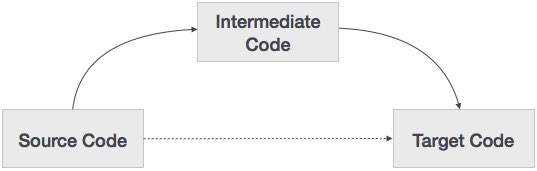
如果编译器将源语言直接翻译成目标机器语言,而没有生成中间代码的选项,那么对于每台新机器,都需要一个完整的原生编译器。
中间代码通过保持所有编译器的分析部分相同,消除了为每台独特机器开发全新完整编译器的需求。
编译器的第二部分,即合成(synthesis),会根据目标机器进行调整。
通过在中间代码上应用代码优化技术,更容易对源代码进行修改以提升代码性能。
中间表示(Intermediate Representation)
中间代码可以用多种方式表示,每种方式都有其自身优势。
高级 IR(High Level IR) - 高级中间代码表示非常接近源语言本身。它们可以轻松从源代码生成,并且我们可以轻松应用代码修改来提升性能。但对于目标机器优化,它不太受欢迎。
低级 IR(Low Level IR) - 这种表示接近目标机器,使其适合寄存器和内存分配、指令集选择等。它适用于机器相关的优化。
中间代码可以是特定语言的(例如 Java 的 Byte Code),也可以是语言无关的(three-address code)。
三地址代码(Three-Address Code)
中间代码生成器从其前一阶段,即语义分析器,接收输入,形式为带有注解的语法树。然后,该语法树可以转换为线性表示,例如后缀表示法。中间代码倾向于机器无关的代码。因此,代码生成器假设具有无限数量的内存存储(寄存器)来生成代码。
例如:
a = b + c * d;
中间代码生成器会尝试将这个表达式分解为子表达式,然后生成相应的代码。
r1 = c * d; r2 = b + r1; a = r2
r 被用作目标程序中的寄存器。
三地址代码最多有三个地址位置来计算表达式。三地址代码可以用两种形式表示:四元式(quadruples)和三元式(triples)。
四元式(Quadruples)
四元式表示中的每条指令分为四个字段:操作符(operator)、arg1、arg2 和结果(result)。上面的例子在四元式格式下表示如下:
| Op | arg1 | arg2 | result |
| * | c | d | r1 |
| + | b | r1 | r2 |
| + | r2 | r1 | r3 |
| = | r3 | a |
三元式(Triples)
三元式表示中的每条指令有三个字段:op、arg1 和 arg2。各自子表达式的结果由表达式的位置表示。三元式与 DAG 和语法树有相似性。在表示表达式时,它们等价于 DAG。
| Op | arg1 | arg2 |
| * | c | d |
| + | b | (0) |
| + | (1) | (0) |
| = | (2) |
在优化过程中,三元式面临代码不可移动的问题,因为结果是位置性的,改变表达式顺序或位置可能会导致问题。
间接三元式(Indirect Triples)
这种表示是三元式表示的改进。它使用指针而不是位置来存储结果。这使得优化器能够自由重新定位子表达式,以生成优化的代码。
声明
在使用变量或过程之前,必须先对其进行声明。声明涉及在内存中分配空间,并在符号表中记录类型和名称。程序可以针对目标机器结构进行编码和设计,但并不总是能够准确地将源代码转换为目标语言。
将整个程序视为过程和子过程的集合,就可以声明所有局部于过程的名称。内存分配以连续方式进行,名称按照程序中声明的顺序分配到内存中。我们使用 offset 变量并将其设置为零 {offset = 0},表示基地址。
源编程语言和目标机器架构在存储名称的方式上可能有所不同,因此使用相对寻址。第一名称从内存位置 0 {offset=0} 开始分配内存,后续声明的下一个名称应紧接第一个名称之后分配内存。
示例:
我们以 C 编程语言为例,其中整数变量分配 2 字节内存,浮点变量分配 4 字节内存。
int a;
float b;
分配过程:
{offset = 0}
int a;
id.type = int
id.width = 2
offset = offset + id.width
{offset = 2}
float b;
id.type = float
id.width = 4
offset = offset + id.width
{offset = 6}
为了将这些细节记录到符号表中,可以使用过程 enter。该过程可能具有以下结构:
enter(name, type, offset)
该过程应在符号表中为变量 name 创建一个条目,将其类型设置为 type,并在数据区中设置相对地址 offset。