编译设计中的准简单文法
在编译设计中采用的 top-down parsing 策略中,我们使用不同类型的文法。如我们所知,文法是定义编程语言语法和结构的基础。其中,simple grammars 提供了易于解析且无歧义的结构,使其非常适合引入基本的 parsing 概念。然而,它们的严格规则限制了在实际场景中的应用。
为了解决这些限制,引入了一种更灵活的文法类型,即quasi-simple grammars。这些文法保留了高效 parsing 所需的简单性,同时在语言表示上提供了更大的灵活性。
在本章中,我们将探讨 quasi-simple grammars 的概念,考察其结构,并理解它们如何扩展 simple grammars 的功能。
什么是 Quasi-Simple Grammars?
Quasi-simple grammars 是一种 context-free grammar,它建立在 simple grammars 的基础上。它们放松了 simple grammars 的一些严格约束。具体来说,quasi-simple grammars 允许 non-terminal 的规则发生重叠,前提是文法能够无歧义地解析。
Quasi-Simple Grammars 的特性
以下是quasi-simple grammars 的主要特性 −
- 放松的规则约束 − 与 simple grammars 不同,一个 nonterminal 的规则可以以相同的 terminal 符号开头,前提是 parsing 保持确定性。
- 适中的解析复杂度 − Quasi-simple grammars 的解析复杂度略高于 simple grammars,但远低于一般的 context-free grammars。
- 更广泛的适用性 − 它们允许更复杂的语言结构,例如嵌套或依赖结构。
Simple Grammars 和 Quasi-Simple Grammars 的区别
为了更好地理解 quasi-simple grammars,让我们将它们与 simple grammars 进行比较 −
| 特性 | Simple Grammar | Quasi-Simple Grammar |
|---|---|---|
| 规则起始符号 | 每个 nonterminal 必须不同 | 在特定条件下可以重叠 |
| Parsing | 非常直接 | 略复杂但高效 |
| 应用 | 有限 | 更广泛,支持中等复杂度 |
Simple grammars 高度限制性,但 quasi-simple grammars 在简单性和灵活性之间取得了平衡,使其在更广泛的使用场景中更实用。
Quasi-Simple Grammars 的结构
在 quasi-simple grammar 中,产生式规则允许一个 nonterminal 的起始符号发生重叠。但是,为了高效的 parsing,这些文法依赖于额外的机制,如 lookahead parsing 或基于栈的处理。
示例:Quasi-Simple Grammar G1
考虑以下文法,G1 −
G1: S → a S b S → a b S →
在这里,我们可以看到 S 有多个规则以 terminal a 开头。这种重叠使得文法成为 quasi-simple 而非严格的 simple。解析此类文法需要进一步分析输入(这称为 lookahead),以决定应用哪条规则。
解析准简单文法
准简单文法的解析过程比简单文法的解析稍复杂一些。使用了诸如前瞻解析和基于栈的解析等技术。这些技术表明解析仍然是高效且确定的。
- 前瞻解析 − 解析器检查输入中的一个或多个后续符号,以确定合适的产生式规则。当重叠规则可以通过下一个输入符号(们)区分时,这种方法很有效。
- 基于栈的解析 − 使用栈来管理中间符号并处理嵌套结构。符号在处理时被压入栈中,并在与输入匹配时弹出。
示例:使用准简单文法 G1 进行解析
让我们使用文法 G1 解析输入字符串 "aaabbb"。
逐步推导
步骤 1 − 从非终符 S 开始。第一个输入符号是 a,因此应用规则 1 −
S → a S b
输入变为 a (S) b。
步骤 2 − 展开第二个 S。下一个输入符号仍是 a,因此再次应用规则 1 −
S → a S b
输入变为 a (a (S) b) b。
步骤 3:展开第三个 S。下一个输入符号是 b,因此应用规则 2 −
S → a b
输入变为 a (a (a b) b) b。
步骤 4 − 组合一切形成最终字符串 −
aaabbb
推导树
此输入的推导树如下 −
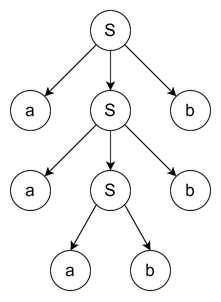
这棵树展示了准简单文法如何处理重叠规则,同时保持无歧义的结构。
准简单文法的应用
当简单文法不足以应对但完整的上下文无关文法又不必要时,准简单文法就很有用。一些常见应用包括 −
- 中间解析 − 准简单文法用于解析的中间阶段。此时语言比简单文法能处理的更复杂,但仍可管理。
- 嵌套结构 − 它们适用于具有中等嵌套的语言。例如平衡括号或条件语句。
- 表达式解析 − 准简单文法可以处理带有嵌套操作的算术表达式。这使得它们在数学或编程语言解析器中很有用。
例如,准简单文法可以解析如下语言结构 −
if (x > 0) {
if (y > 0) {
print("Positive");
}
}
这里,if 语句的重叠规则可以使用前瞻解析来管理。
准简单文法的优势
准简单文法具有以下几项优势:
- 灵活性 − 它们比简单文法能表达更复杂的结构。
- 高效解析 − 尽管更复杂,准简单文法仍然比一般的上下文无关文法更容易解析。
- 更广泛的应用 − 它们在简单性和表达能力之间取得了平衡。这使得它们适用于各种编程语言结构。
准简单文法的局限性
准简单文法存在以下局限性 −
- 解析复杂度增加 − 与简单文法相比,准简单文法需要更复杂的解析技术。
- 潜在歧义 − 如果设计不慎,准简单文法可能会引入歧义。
- 表达能力有限 − 虽然比简单文法更具表达力,但准简单文法无法描述所有上下文无关语言。
准简单文法:实际相关性
准简单文法在编译器的语法分析阶段特别有价值。它们提供了简单文法的严格规则与一般上下文无关文法的无限制特性之间的中间地带。
例如 − 在词法分析中,准简单文法可以定义如标识符和关键字之类的模式。在语法分析中,它们可以处理中等嵌套的结构,如循环、条件语句或函数调用。
Conclusion
在本章中,我们探讨了准简单文法(quasi-simple grammars)的概念及其在编译器设计中的重要性。我们考察了它们如何通过允许非终结符的重叠规则来扩展简单文法,从而能够处理更复杂的语言结构。
通过示例,我们看到了准简单文法如何在简单性和灵活性之间取得平衡,以促进高效的解析。准简单文法提供了一种实用的方法来描述中等复杂度的语言,而无需一般上下文无关文法的全部复杂性。